1 前言
在大数据背景下, 数据倾斜是一个频发问题, 有时候我们可能会有疑问, 为什么一个处理几千万数据量的任务比一个处理几亿数据量的任务耗时还要长很多, 这里大概率是因为任务产生了数据倾斜. 在日常工作中, 数仓工程师一般可以比较好的处理倾斜问题, 但对于其他非数仓的数据工作者, 倾斜就相对难处理一些, 本文就尽可能全的说清楚数据倾斜是什么, 为什么产生以及如何解决 .
2 不得不说的MapReduce
MapReduce的核心思想是”分而治之”, 将一个复杂的问题分解为多组相似或相同的子问题, 通过解决子问题, 来达到原问题的解决, 类似于归并排序. 我们本次说的数据倾斜仅限于使用MapReduce计算引擎的场景, 其他如Spark, Flink等, 解决思路基本一致 .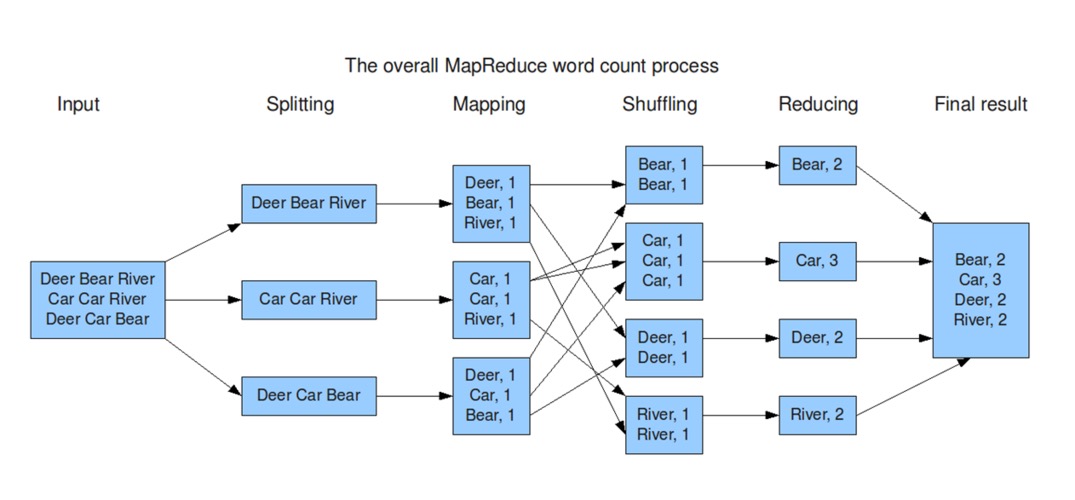
想要解决MapReduce中产生的数据倾斜, 就要对MapReduce有一定的了解, 以WoreCount举例,处理过程一共分为以下几个关键步骤:
数据切分
对于需要Input的所有数据, 如果单个文件小于128MB(默认设置,可修改), 则一个文件会启动一个MapTask, 如果大于128MB, 则会被切分; 举个栗子, 本次任务的Input为3个文件, 其大小分别为5MB, 120MB和200MB, 则会启动4个MapTask, 分别处理5MB, 120MB, 128MB和72MB的数据 ;
Map处理
数据读取 : 读取任务对应的数据文件, 将数据读取到任务中;
数据处理 : 将数据按写定的逻辑处理完成,并将相同的key放在一起, 以WordCount为例, 每个单词被处理为(单词,1)的形式, 并且在单个MapTask内相同的单词被放在了一起;
数据落地 : 处理好的数据会落磁盘, 形成一个个内部有序的文件, 等待Reduce拉取
Reduce处理 :
数据拉取 : Reduce的输入是Map的输出, 在所有Map输出完成后, Reduce会把Map产生的所有文件中属于自己的拉取到一起, 从Map的输出, 到Reduce的拉取, 这个过程被称为Shuffle(狭义)
数据处理 : 相同的key会在一个ReduceTask内, 按既定的聚合逻辑处理数据, 以WordCount为例, 相同的单词被一个Reduce拉取到一起, 并进行数字的聚合, 得出此单词的出现的次数 ;
数据落地 : Reduce处理完成后, 会将结果落地 ;
任务结束 : 所有的Map(无Reduce情况下)或Reduce结束则总任务完成
3 为什么会产生数据倾斜
我们将上面的MapReduce执行图简化一下, MapTask按设置切分数据, 对数据进行处理后给到ReduceTask处理, 最终处理完成数据落地, 而数据倾斜就发生在从Map处理结束到Reduce处理结束这部分.
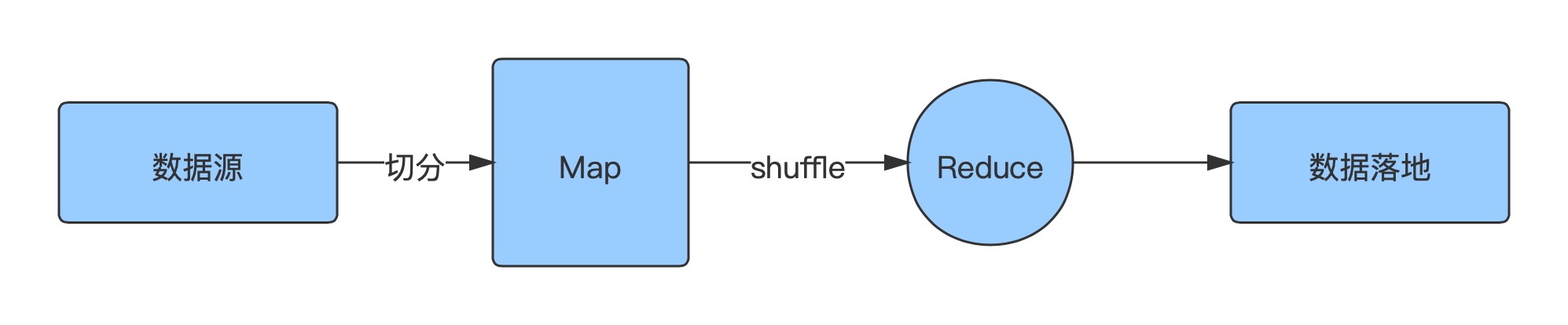
整个MapReduce中有两个原则
Map处理完, 才会启动Reduce
所有Reduce处理完, 任务才会结束
而当Reduce任务中, 有一个或较少量的Task比其他Task处理任务所需要的时间长出几倍甚至几十倍, 这种现象就叫数据倾斜. 那为什么会产生数据倾斜呢? 其实原因很简单, 从字面上就可以理解, 数据”倾斜”到了一角, 那处理这部分数据的任务耗时就会比其他任务多, 如果”倾斜”的很严重, 这个任务耗时就会特别久, 即使其他任务都已经完成, 也要等待这个Task完成, 整体的任务才能结束.
数据倾斜会导致以下几个重点问题
1、任务长时间挂起, 资源得不到释放, 利用率低;
2、增加OOM的风险, 导致任务直接失败;
3、任务的执行时长超出预期, 导致不能满足时效性的要求;
4 如何解决数据倾斜
上面我们介绍了数据倾斜原因是少量的Task处理了大量的数据, 以WordCount为例, 总共10个单词, “Car”这个单词就出现了9亿次, 那么负责处理”Car”这个单词的ReduceTask就会因为数据量太多而增加处理数据的时间, 即使其他ReduceTask都结束, 也要等待它执行完成, 这个任务最终才能执行成功.
解决数据倾斜需要对症下药, 基本可以分为以下几种思路 :
1、尽量减少Map的输出
通过Where条件提前过滤
Reduce的输入是Map的输出, 如果有10亿数据, 我们只需要其中一部分参与计算, 则可以使用Where语句, 将不需要参与计算的数据优先过滤掉, 这样Reduce处理的总量减少, 即使发生了数据倾斜, 其严重程度也会降低.
在Map输出时, 提前进行预聚合 ( set hive.map.aggr=true; )
如果我们可以在Map输出的时候, 就对数据提前进行预聚合, 那么Reduce拉取的数据总量也会减少, 特别在数据倾斜比较严重的情况下, 一个MapTask可能处理的都是同一个key, 如果可以预聚合, 那这个MapTask的输出可能从原来的千万,亿降低至1条.
同样以WordCount为例, 在MapTask时, “C C C”这一条, 因为开启了预聚合(combiner), 从原来的输出3条数据, 变为只输出一条, 极大的降低了数据输出.
2、打散集中的数据Key, 用尽量多的任务去处理
因为MapReduce的特性, 同一个key在默认情况下只会有一个Reduce任务处理, 如果我们能让更多的Task去处理这批数据, 那处理的速度就会变快, 理论上每多一个任务处理, 速度就会提升一倍, 那么怎么样才能让更多的任务去处理相同Key值的数据呢? 分为以下几种情况 :
Group By时, 维度枚举过少, 或某Key值过多
这种情况下, 一般可以通过配置 set hive.groupby.skewindata=true;
这种方法比较简单, 直接配置hive的参数, 在配置后, 原本的查询计划会被分为两个MapReduce任务, 第一个任务在Map输出时, 会随机将数据分发到Reduce中, 而不是按Key值来分发, 相同的Key可能会被分发到不同的Reduce中处理, 在Reduce做了一次聚合后, 会再将数据给到下一个MapReduce , 这次不再随机分配, 而是按照相同的Key值在一个Reduce中处理, 通过中间打散一次, 来解决数据倾斜;
3、Join时产生了数据倾斜
数据在join时同样有可能产生数据倾斜, 如果其中有一个表比较小, 可以开启MapJoin(默认打开). 在Join这里重点说明几个实际场景
a. 关联键字段有大量null值, 且null值记录不需要
当关联字段有大量null值时, 所有的null都会交给一个Reduce处理, 在结果不需要这些null值时, 需要提前过滤
b. 关联字段有大量null值, 且null值记录需要
在管理的ON条件里, 将null值变为字符串+随机值的形式, 例如 ON t1.id = if(t2.id is null, concat(‘hive’,rand(),t2.id) ,这样就会将null值随机分发到不同的Reduce中处理, 因为原本就Join不上, 所以对结果没有影响
c. 不同数据类型的字段关联
当关联键两边的数据类型不一致时, 也会发生数据倾斜的问题(可能也会出现join后数据不对的情况), 这种情况下, 需要在ON条件里, 使用CAST将其转换为相同类型
5 总结
数据倾斜问题对资源使用和数据产出时效性都有较大的影响, 且通过工具实现治理比较困难, 是数据治理的一大核心问题. 想要解决数据倾斜就一定要知道到底是因为什么而产生了数据倾斜, 再对照上文的思路, 一一解决.


