1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
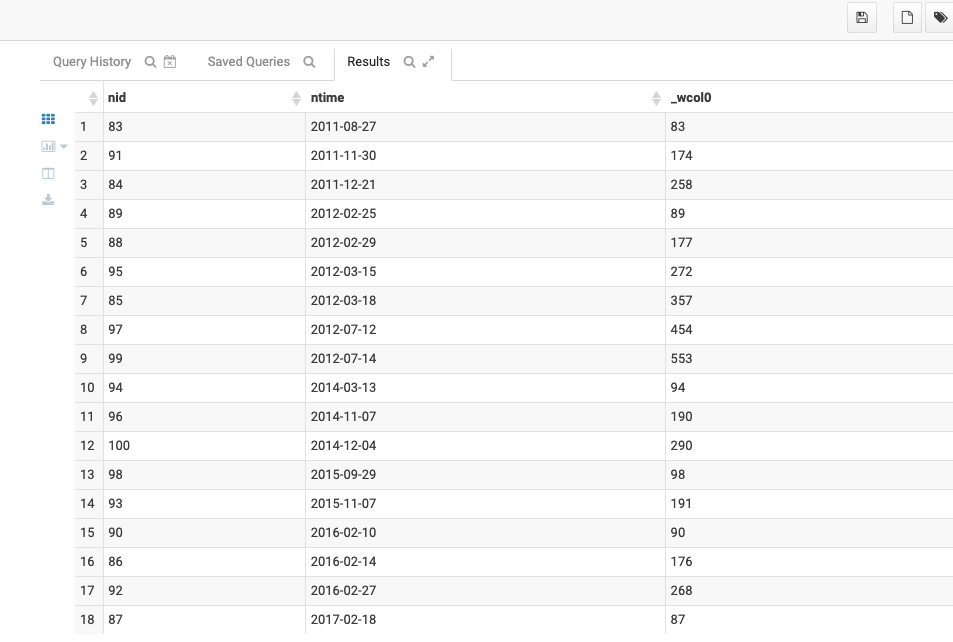
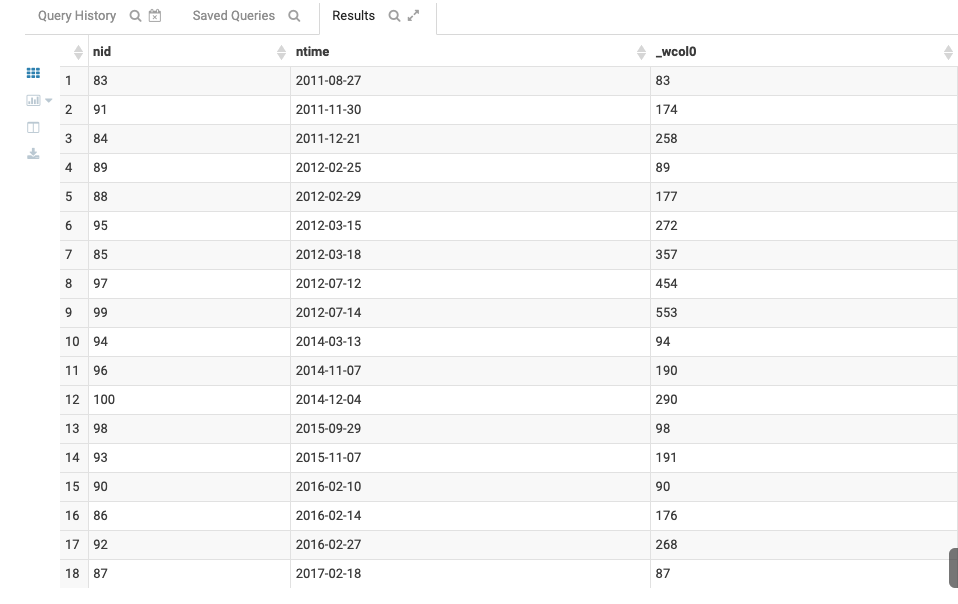
| select
nid,ntime,sum(nid) over(partition by year(ntime) order by ntime )
from zxz_5
INFO : Compiling command(queryId=hive_20210625110909_e1c79678-b33a-4e7f-be24-80f53eab913c): select
nid,ntime,sum(nid) over(partition by year(ntime) order by ntime )
from zxz_5
INFO : Semantic Analysis Completed
INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:nid, type:bigint, comment:null), FieldSchema(name:ntime, type:string, comment:null), FieldSchema(name:_wcol0, type:bigint, comment:null)], properties:null)
INFO : Completed compiling command(queryId=hive_20210625110909_e1c79678-b33a-4e7f-be24-80f53eab913c); Time taken: 0.075 seconds
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Executing command(queryId=hive_20210625110909_e1c79678-b33a-4e7f-be24-80f53eab913c): select
nid,ntime,sum(nid) over(partition by year(ntime) order by ntime )
from zxz_5
INFO : Query ID = hive_20210625110909_e1c79678-b33a-4e7f-be24-80f53eab913c
INFO : Total jobs = 1
INFO : Launching Job 1 out of 1
INFO : Starting task [Stage-1:MAPRED] in serial mode
INFO : Number of reduce tasks not specified. Estimated from input data size: 1
INFO : In order to change the average load for a reducer (in bytes):
INFO : set hive.exec.reducers.bytes.per.reducer=<number>
INFO : In order to limit the maximum number of reducers:
INFO : set hive.exec.reducers.max=<number>
INFO : In order to set a constant number of reducers:
INFO : set mapreduce.job.reduces=<number>
INFO : number of splits:1
INFO : Submitting tokens for job: job_1576480232731_834434
INFO : The url to track the job: http://emr-master.izhikang.com:8088/proxy/application_1576480232731_834434/
INFO : Starting Job = job_1576480232731_834434, Tracking URL = http://emr-master.izhikang.com:8088/proxy/application_1576480232731_834434/
INFO : Kill Command = /opt/cloudera/parcels/CDH-5.9.0-1.cdh5.9.0.p0.23/lib/hadoop/bin/hadoop job -kill job_1576480232731_834434
INFO : Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
INFO : 2021-06-25 11:09:42,608 Stage-1 map = 0%, reduce = 0%
INFO : 2021-06-25 11:09:46,696 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 2.07 sec
INFO : 2021-06-25 11:09:51,794 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 4.58 sec
INFO : MapReduce Total cumulative CPU time: 4 seconds 580 msec
INFO : Ended Job = job_1576480232731_834434
INFO : MapReduce Jobs Launched:
INFO : Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 4.58 sec HDFS Read: 16236 HDFS Write: 319 SUCCESS
INFO : Total MapReduce CPU Time Spent: 4 seconds 580 msec
INFO : Completed executing command(queryId=hive_20210625110909_e1c79678-b33a-4e7f-be24-80f53eab913c); Time taken: 13.853 seconds
INFO : OK
|
 Hive 中parse_url的使用
Hive 中parse_url的使用


