事实表设计
学习《大数据之路》第11章,《事实表设计》摘要。
事实表基础
事实表特性
事实表作为数据仓库维度建模的核心,进进围绕着业务过程来设计,
通过获取描述业务过程的度量来表达业务过程,包含了引用的维度和业务过程有关的度量。
事实表中一条记录所表达的业务细节成都被称为粒度。
通常粒度可以通过两种方式表述:
1、一种是维度属性组合所示的细节程度;
2、一种是所表示的具体业务含义。
作为度量业务过程的事实,一般为整形或浮点型的是十进制数值,
有可加性、半可加性和不可加性三种类型。
1、可加性事实是指可以按照与事实表关联的任意维度进行汇总。
2、半可加性事实只能按照特定维度汇总,不能对所有维度汇总。还有一种度量完全不具备可加性,比如比率型事实。
3、不可加性事实可分解为可加的组件来实现聚集。
维度属性也可以存储到事实表中,这种存储到事实表中的维度列被称为**”维度退化”**。
与其他存储在维度中的维度一样,退化维度也可以用来进行事实表的过滤查询、实线聚合操作等。
事实表有三种类型:
1、事务事实表
事务事实表用来描述业务过程,跟踪空间或时间上某点的度量事件,保存的是最原子的数据,也称为”原子事实表”。
2、周期快照事实表
周期快照事实表以具有规律性的、可预见的时间间隔记录事实,时间间隔如每天、每月、每年等。
3、累计快照事实表
累计快照事实表用来描述过程开始和结束之间的关键步骤事件,覆盖过程的整个生命周期,通常具有多个日期来记录关键时间点,当过程随着生命周期不断变化时,记录也会随着过程的变化而被修改。
事实表设计原则
原则1:尽可能包含所有与业务过程相关的实时
事实表设计的目的是为了度量业务过程,所以分析哪些事实与业务过程有关是设计中非常重要的关注点。
在事实表中应该尽量包含所有与业务过程相关的事实,即使存在冗余,但是因为事实通常为数字型,带来的存储开销也不会很大。
原则2:只选择与业务过程相关的事实
在现则事实时,应该注意只选择与业务过程有关的事实。
比如在订单的下单这个业务过程的事实表设计中,不应该存在支付金额这个表示支付业务过程的事实。
原则3:分解不可加性事实为可加的组件
对于不具备可加性条件的事实,需要分解为可加的组件。
比如订单的优惠率,应该分解为订单原价金额与订单优惠金额两个事实存储在事实表中。
原则4:在选择维度和事实之前必须先声明粒度
粒度的声明是事实表设计中不可忽视的重要一步,粒度用于确定事实表中一行所表示业务的细节层次,
决定了维度模型的扩展性,在选择维度和事实之前必须先声明粒度,
且每个维度和事实必必须与所定义的粒度保持一致。
在设计事实表的过程中,粒度定义的越细越好,建议从最低级别的原子粒度开始,
因为原子粒度提供了最大限度的灵活性,可以支持无法预期的各种细节层次的用户需求。
原则5:在同一个事实表中不能有多重不同粒度的事实
事实表中的所有事实需要与表定义的粒度保持一致,在同一个事实表中不能有多种不同粒度的事实。
原则6:事实的单位要保持一致
对于同一个事实表中事实的单位,应该保持一致。
原则7:对事实的null值要处理
对于事实表中事实度量为null值的处理。
原则8:使用退化维度提高事实表的易用性
在大数据领域的事实表设计中,则大量采用退化维度的方式,在事实表中存储各种类型的常用维度信息。
这样设计的目的主要是为了减少下游用户使用时关联多个表的操作,直接通过退化维度实线对事实表的过滤查询、控制聚合层次、排序数据以及定义主从关系等。
通过增加荣誉存储的方式减少计算开销,提高使用效率。
事实表设计方法
对于维度模型设计采用四部设计方法:
- 1、选择业务过程
- 2、声明粒度
- 3、确定维度
- 4、确定事实
在当前的互联网大数据环境下,面对复杂的业务场景,为了更有效、准确地进行维度模型建设,基于Kimball的四部维度建模方法进行一下改进。
第一步:现在业务过程及确定事实表类型。
在明确了业务需求以后,接下来需要进行详细的需求分析,对业务的整个生命周期进行分析,明确关键的业务步骤,从而选择与需求有关的业务过程。
业务过程通常使用行为动词表示业务执行的活动。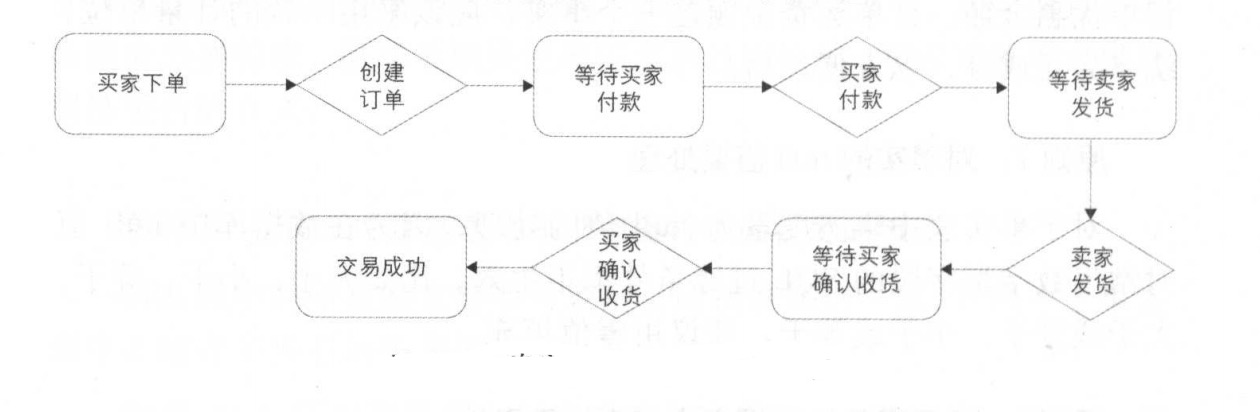
第二步:声明粒度。
粒度的声明是事实表建模非常重要的异步,意味着精确定义事实表的每一行所表示的业务含义,粒度传递的是与事实表度量有关的细节层次。
明确的粒度能确保对事实表中行的意思的理解不会产生混淆,保证所有的事实按照同样的细节层次记录。
应该尽量选择最细级别的原子粒度,以确保事实表的应用具有最大的灵活性。同事对于订单过程而言,粒度可以被定义为最细的订单级别。
第三步:确定维度。
完成粒度声明以后,也就意味着确定了主键,
对应的维度组合以及相关的维度字段就可以确定了,
应该选择能够描述清楚业务过程所处的环境的维度信息。
第四步:确定事实。
事实可以通过回答”过程的度量是什么“来确定。应该选择与业务过程有关的所有事实,且事实的粒度要与所生命的事实表的粒度一致。
事实有可加性、半可加性、非可加性三种声明,需要将不可加性事实分解为可加的组件。
第五步:冗余维度。
在传统的维度建模的星形模型中,对维度的处理是需要单独存放在专门的为表中的,
通过事实表的外键获取维度。
这样做的目的是为了减少事实表的维度冗余,从而减少存储消耗。
而在大数据的事实表模型设计中,考虑更多的是提高下游用户的使用率,降低数据获取的复杂性,
减少关联的表的数量。所以通常实施表中会冗余方便下游用户使用的常用维度,以实现对事实表的过滤查询、控制聚合层次、排序数据以及定义主从关系等操作。
事务事实表
设计过程
任何类型的事件都可以被理解为一种事务。
事务事实表,既针对这些过程构建一类事实表,用以跟踪定义业务过程的个体行为,提供丰富的分析能力,作为数据仓库原子的明细数据。
1、选择业务过程
Kimball维度建模理论认为,为了便于进行独立的分析研究,应该为每个业务过程简历一个事实表。
对于是否将不同业务过程放到同一个事实表中。2、确定粒度
业务过程选定以后,就要针对每个业务过程确定一个粒度,既确定事务事实表每一行所表达的细节层次。
3、确定维度
选定好业务过程并且确定粒度后,就可以确定维度信息了。
4、确定事实
作为过程度量的核心,事实表应该包含与其描述过程有关的所有事实。
根据Kimball维度建模理论,经过以上四步。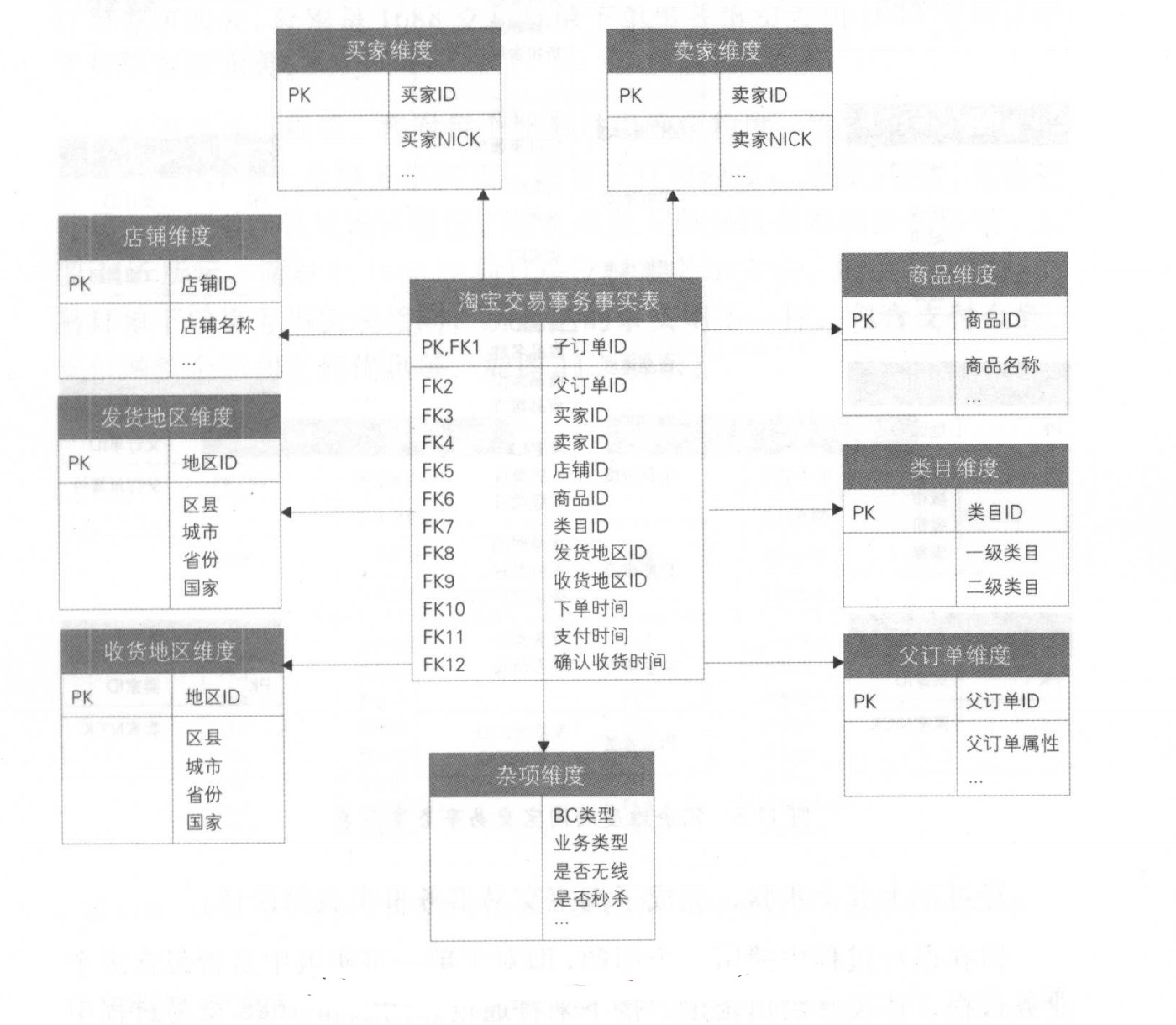
- 5、冗余维度
在确定维度时,Kimball维度建模理论建议在事实表中只保存这些维表的外键,而淘宝交易事务事实表在Kimball维度建模基础之上做了进一步的优化,
将买卖家星级、标签、店铺名称、商品类型、商品特征、商品属性、类目层级等维度属性都冗余到事实表中,提高对事实表进行过滤查询、统计聚合的效率。
单事务事实表
单事务事实表,针对每个业务过程设计一个事实表。
这样设计的有点不言而喻,可以方便地对每个业务过程进行独立的分析研究。
多事务事实表
多事务事实表,将不同的事实放到同一个事实表中,即同一个事实表包含不同的业务过程。
多事务事实表再设计时有两种方法进行实时的处理:
- 1、不同业务过程的事实使用不同的事实字段进行存放。
- 2、不同业务过程的事实使用同一个事实字段进行存放,但增加一个业务过程标签。
多事务事实表的选择
原书206页
两种多事务事实表的设计方式,在实际应用中需要根据业务过程进行选择。
由于是多事务事实表,因此在事实表中包含多个业务过程:
- 1、当不同业务过程的度量比较相似、差异不大时,可以采用第二种多事务事实表的设计方式,
使用同一个字段来表示度量数据。但这种方式存在一个问题——在同一个周期内会存在多条记录。- 2、当不同业务过程的度量差异较大时,可以选择第一种多事务事实表的设计方式,将不同业务过程的度量使用不同字段冗余到表中,
非当前业务过程则置零表示。这种方式所存在的问题是度量字段零值较多。
两种事实表对对比
单事务还是表和多事务事实表的设计过程,
目前两类事实表都有实际的应用,但具体哪一种设计方式更优。
分析如下:
- 1、业务过程
对于单事务事实表,一个业务过程简历一个事实表,只反映一个业务过程的事实;
对于多事务事实表,在同一个事实表中反映多个业务过程。
多个业务过程是否放到同一个事实表中,首先需要分析不同业务过程质检的相似性和业务源系统。 - 2、粒度和维度
在考虑是否采用单业务事实表还是多业务事实表时,另一个关键点就是粒度和维度,
在确定好业务过程后,需要基于不同的业务过程确定粒度和维度,当不同业务过程的粒度相同,
同事拥有相似的维度时,此时就可以考虑采用多事务事实表。
如果粒度不同,则必定是不同的事实表。 - 3、事实
对于不同的业务过程,事实往往是不同的,单事务事实表在处理事实上比较方便和灵活,
仅仅提现同一个业务过程的事实即可;
而多业务事实表由于多个业务过程,所以有更多的事实需要处理。
如果单一业务过程的事实比较多,同事不同业务过程的事实又不相同,则可以考虑使用单事务事实表,
处理更加清晰若使用多事务事实表,则会导致事实表零值活空值字段较多。 - 4、下游业务使
单事务事实表对于下游用户而言更容易理解,关注哪个业务过程就使用相应的事务事实表;而多事务事实表包含多个业务过程,用户使用时往往较为困惑。 - 5、计算存储成本
针对多个业务过程设计事务事实表,是采用单事务事实表还是多事务事实表,对于数据仓库的计算存储成本也是参考点之一,当业务过程数据来源于同一个业务系统,具有相同的粒度和维度,且维度较多而事实相对不多时,此时可以考虑使用多事务事实表,不仅其加工计算成本较低,同时在存储上也相对节省,是一种较优的处理方式。
| 单事务事实表 | 多事务事实表 | |
|---|---|---|
| 业务过程 | 一个 | 多个 |
| 粒度 | 相互间不相关 | 相同粒度 |
| 维度 | 相互间不相关 | 一致 |
| 事实 | 只取当前业务过程中的事实 | 保留多个业务过程中的事实,非当前业务过程中的事实需要置零处理 |
| 冗余维度 | 多个业务过程,则需要冗余多次 | 不同的业务过程只需要冗余一次 |
| 理解程度 | 易于理解,不会混淆 | 难以理解,需要通过标签来限定 |
| 计算存储成本 | 较多,每个业务过程都需要计算存储一次 | 较少,不同业务过程融合到一起,降低了存储计算量,但是非当前业务过程的度量存在大量零值 |
事实的设计准则
- 1、事实完整性
事实表包含与其描述的过程有关的所有事实,即尽可能多地获取所有的度量。 - 2、事实一致性
在确定事务事实表的事实时,明确存储每一个事实以确保度量的一致性。 - 3、事实可加性
事实表确定事实时,往往会遇到非可加性度量,比如分摊比例,利率等,虽然它们也是下游分析的关键点,但往往在事务事实表中关注更多的是可加性事实,下游用户在聚合统计时更加方便。
周期快照事实表
事务事实表可以很好地跟踪一个事件,并对其进行度量,以提供丰富的分析能力。
然而,当需要一些状态度量时,比如账户余额、买卖家星级、商品库存、卖家累积交易额等,增需要聚集与之相关的事务才能进行识别计算;
或者聚集事务无法识别,比如温度等。
等于这些状态度量,事务事实表是无效率的,而这些度量也和度量事务本身一样是有用的,因此,维度建模理论给出了第二种常见的事实表———周期快照事实表,简称”快照事实表”。
快照事实表在确定的间隔对实体的度量进行抽样,这样可以很容易地研究实体的度量值,而不需要聚集长期的事务历史。
特性
快照事实表的设计有一些区别于事务事实表设计的性质。
事务事实表的粒度能以多种方式表达,但快照事实表的粒度通常以维度形式声明;
事务事实表是稀疏的,但快照事实表是稠密的;
事务事实表中的事实是完全可加的,单快照模型将至少包含一个用来展示半可加性之的事实。
- 1、用快照采样状态
快照事实表以预定的间隔采样状态度量。这种间隔联合一个或多个维度,将被用来定义快照事实表的粒度,每行都将包含记录所涉及状态的事实。 - 2、快照粒度
事务事实表的粒度可以通过业务过程中所涉及的细节程度来描述,单快照事实表的粒度通常总是被多维声明,可以简单地理解为快照需要采样的周期以及声明将被采样。 - 3、密度与稀疏性
快照事实表和事务事实表的一个关键区别在密度上。事务事实表是稀疏的,只有当天发生的业务过程,事实表才会记录该业务过程的事实。
稠密性是快照事实表的重要特征,如果在每个快照周期内不记录行,比如和事务事实表一样,那么确定状态将变得非常困难。 - 4、半可加性
在快照事实表中收集到的状态度量都是半可加的。
与事务事实表的可加性事实不同,半可加性事实不能根据时间维度获得有意义的汇总结果。
对于快照事实表的设计步骤可以归纳为:
- 1、确定快照事实表的快照粒度。
- 2、确定快照事实表采样的状态度量。
注意事项
- 1、事务与快照成对设计
数据仓库维度建模时,对于事务事实表和快照事实表往往都是成对设计的,互相补充,以满足更多的下游统计分析需求,特别是在事务事实表的基础上可以加工快照事实表。 - 2、附加事实
快照事实表在确定状态度量时,一般都是保存采样周期结束时的状态度量。
但是也有分析需求需要关注上一个采样周期结束时的状态度量,而又不愿意多次使用快照事实表,因此一般在设计周期快照事实表时会附加一些上一个采样周期的状态度量。 - 3、周期到日期度量
设计周期快照事实表时,针对多种周期到日期的度量设计了不同的快照事实表。
累积快照事实表
对于类似于研究时间之间时间间隔的需求,采用累积快照事实表可以很好地解决。
设计过程
- 1、 选择业务过程
- 2、 确定粒度
- 3、 确定维度
- 4、 确定事实
- 5、 退化维度



