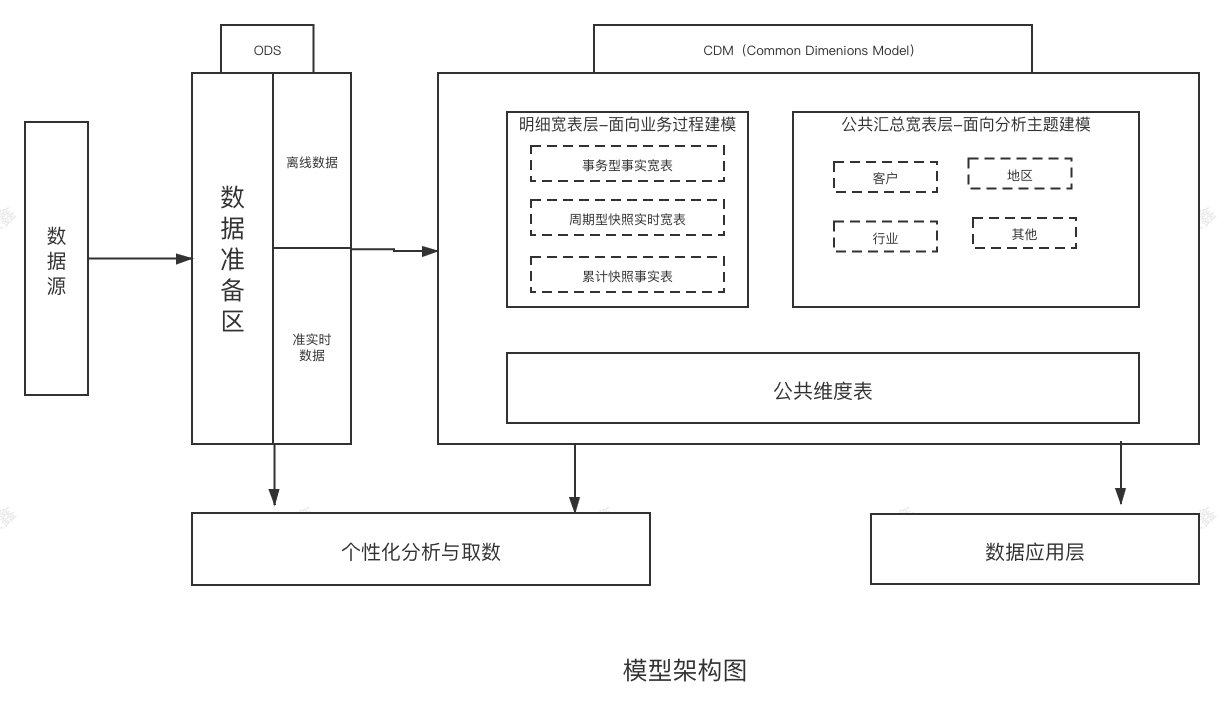
模型设计
模型层次

把表数据模型分为三层:
- 1 、操作数据层(ODS)
- 2、公共维度模型层(DM) , 包括明细数据层(DWD)和汇总数据层(DWS)
- 3、应用数据层(ADS)
操作数据层(ODS)
把操作系统数据几乎无处理地存放在数据仓库系统中。
同步:结构化数据增量或全量同步到 MaxCompute
结构化:非结构化(日志)结构化处理并存储至lj MaxComputes。
累积历史、清洗:根据数据业务需求及稽核和审计要求保存历史数据、清洗数据。
公共维度模型层(CDM)
存放明细事实数据、维表数据及公共指
标汇总数据 其中明细事实数据、维表数 一般根据 ODS 层数据加工
生成 :公共指标汇总数据 般根据维表数据和明细事实数据加工生成。
CDM 层又细分为 DWD 层和 DWS 层,分别是明细数据层和汇总数
据层,采用维度模型方法作为理论基础 更多地采用 些维度退化手法,
将维度退化至事实表中,减少事实表和维表的关联 ,提高明细数据表的易用性;
同时在汇总数据层,加强指标的维度推华,采取更多的宽表化手段构建公共指标数据层,
提升公共指标的复用性,减少重复加工。
其主要功能如下:
- 1、组合相关和相似数据:采用明细宽表,复用关联计算,减少数据扫描。
- 2、公共指标统一加工:基于OneData体系构建命名规范、口径一致、算法统一的统计指标,
为上层数据产品、应用和服务提供公共指标;简历逻辑汇总宽表。 - 3、建立一致性维度:建立一致的数据分析维表,降低数据计算口径、算法不同意的风险。
应用数据层(ADS)
存放数据产品个性化的统计指标数据,根据CDM层和ODS层加工生层。
- 1、个性化指标加工:不公用性、复杂性(指数型、比值型、排名型指标)。
- 2、基于应用的数据组装:大宽表集市、横表转纵表、趋势指标串。
数据调用服务优先使用公共维度模型层(CDM)数据,当公共层没有数据时,需平谷是否需要创建公共数据,
当不需要建设公用的公共层时,方可直接使用操作数据层(ODS)数据。
应用数据层(ADS)作为产品特有的个性化数据一般不对外提供数据服务,但是ADS作为被服务方也需要遵守这个约定。
基本原则
1、高内聚和低耦合
一个逻辑或者物理模型由哪些记录和字段组成,应该遵循最基本的软件设计方法论
的高内聚和低耦合原则。
主要从数据业务特性和访问特性两个角度来考虑:
- a、将业务相近或者相关、粒度相同的数据设计为一个逻辑或者物理模型;
- b、将高概率同时访问的数据放一起,将低概率同时访问的数据分开存储。
2、核心模型与扩展模型分离
建立核心模型与扩展模型体系,核心模型包括的字段支持常用的核心业务,
扩展模型包括的字段支持个性化或少量应用的需要,
不能让扩展模型的字段过度侵入核心模型,
以免破坏核心模型的架构简洁性与可维护性。
3、公共处理逻辑下沉及单一
越是底层公用的处理逻辑越应该在数据调度依赖的底层进行封装与实现,
不要让公用的处理逻辑暴露给应用层实现,不要让公共逻辑多处同时存在。
4、成本与性能平衡
适当的数据冗余可换取查询和刷新性能,不宜过度冗余与数据复制。
5、数据可回滚
处理逻辑不变,在不同时间多次运行数据结果确定不变。
6、一致性
具有相同含义的字段在不同表中的命名必须相同,必须使用规范定义中的名称。
7、命名清晰、可理解
表命名需清晰、一致,表名需易于消费者理解和使用。



