网易云音乐数仓建模实践
数仓是商业智能的基础,它为OLAP、数据挖掘提供分析和决策支持。本文以在声波业务中的实践经历,总结了如何开始构建一个数仓模型、如何配置数据任务流调度、以及如何在自助取数上抽象模型配置cube!
声波app是网易云音乐推出的一款主打语音交友的陌生人社交软件,能够进行语音连麦、1V1聊天、娱乐交友等互动的平台。
声波基础数仓模型
1.初期设计
早期的声波数仓模型
早期的声波数仓模型梳理了主要的业务域以及核心业务过程,构建的总线矩阵如上图所示,当然现在看来是有很多不够完善的地方。
2.思考
因此,当有机会接手一个新APP时,该如何构建一个完整的数据仓库模型?这里总结了相关经验以及踩过的坑,建议按照以下步骤进行:
step1:数据调研
数据调研步骤非常重要,主要目的是确定需求及需求分析。可以通过调查或访谈等形式来了解,主要分为两部分。
(1)咨询不同需求方对数据仓库的需求
不同分工人员(分析师、策划、运营、财务等各个部门)对数据仓库的需求不同,前期需要咨询他们的初期、中期、长期的目标,了解了目标,才能够建设有利的数据仓库。以下是声波业务的需求归纳:
分析师的初期的期望是能够产出自上而下的,可直接监控业务大盘的数据,中长期是对新的产品功能做监控,帮助业务实现营收KPI;
策划在初期的期望是能够对用户在注册登录环节的流失做些分析,中期是不断扩展拉新用户方式,并对用户做渠道归因,同时增加新的产品功能体验,提升用户留存,长期目标是引导用户付费,实现年终营收KPI,需要分析相关数据;
运营的目标是为产品提供运营抓手,组织月度活动,以及对厅主做培训,引导用户付费,其中需要分析活动效果及厅主培训成果;
财务的需求是按月要求输出各类型用户的消费、收益、充值、毛利率预估、波币的movement等监控数据。
(2)整体的业务数据框架
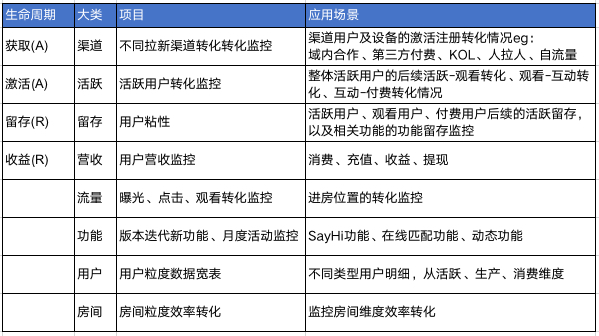
这里按照AARRR模型整理了声波业务的整体框架,如下表所示:
step2:主题域
主题域一般可以按照企业的部门划分,也可以按照业务过程或者业务板块中的功能模块进行划分,这里遵循云音乐主端的规范,将一级主题域划分为参与者、服务及产品,版权及协议、公共、事实这5个大的主题域,二级细节分类在下文中详述。
step3:定义维度与构建总线矩阵
维度建模中我们选用了Kimball维度建模方法,在定义好主题域之后,需要对具体对业务过程做分类。
下面是对声波重新构建了总线矩阵,结构大致如表所示:
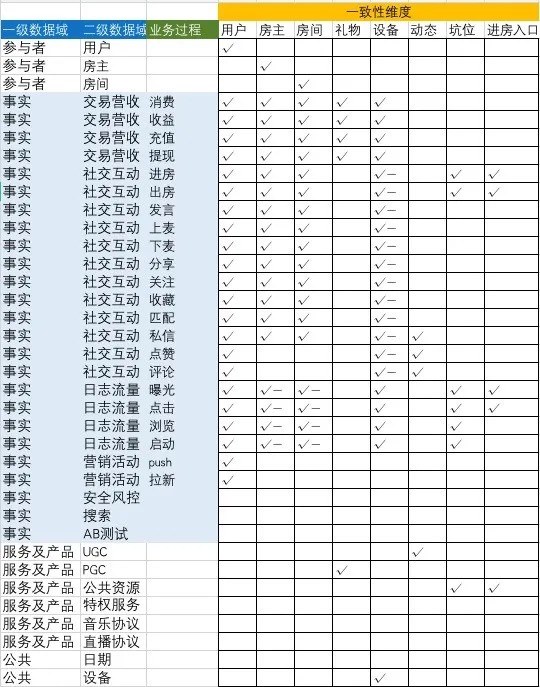
其中打勾的是指在对应的业务过程功能与一致性维度下有关联性,由此来构建事实表与维度表。
step4:明确指标统计
统计指标一般是来源于分析师梳理的监控报表。其中指标=时间周期+统计粒度+业务过程的度量(描述)。请注意,口径一般包含业务口径和技术口径。一般业务口径分析师经与策划等沟通后会给到一个明确统一的口径,技术口径可能需要我们回填给业务。
声波的常用统计指标一般包括(时间周期)近1/3/7/15/30日的(统计粒度)用户的(业务过程)进房次数、进房时长、消费金额、是否留存等等。
step5:结果验证
构建数据仓库,主要是为我们及下游使用方分析数据,以赋能产品,所以数据的准确性至关重要,可以先通过网易有数大数据平台提供的数据测试中心的测试功能进行测试、找前辈们review代码或者通过与已有报表中相同指标进行核对,然后再交由分析师配置报表。
至此,我们将数据做了一个以业务过程为分类的纵向划分,下面要开始对数据做横向的分层。
声波任务流建设
2.1现有设计
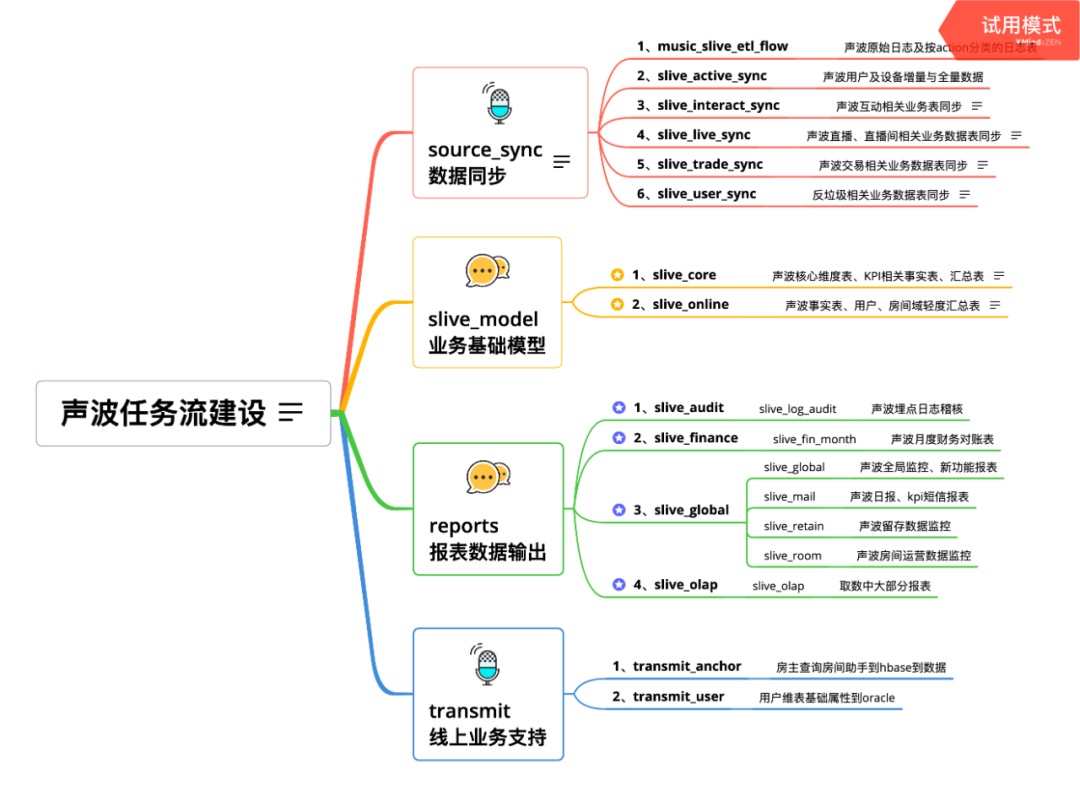
声波数据任务流的地址为:XXXX。主要分为source_sync、slive_model、reports、transmit四个目录。下图中详细描述了各文件存放的数据内容:
2.2思考
如何进行数据分层?
常规的数据仓库模型分层一般包括ODS贴源数据层,DIM维度层,DWD明细数据层,DWS轻(中/重)度汇总层以及ADS应用数据层。在分层中我们需要思考以下问题:
业务数据是根据什么(维度、粒度)汇总的,衡量标准是什么?
eg:声波划分的粒度包括:用户粒度、房间粒度、用户+房间粒度、动态粒度、用户+动态粒度,衡量标准主要是各粒度下的各种指标:次数、时长、金额等等。
DIM该如何设计?DWD和DWS应该如何设计?是否有公共的指标?
eg:DIM是观察业务的角度,建议可以设计主维表(一般为直接从业务库中同步来的、包含常用的属性、稳定性高)和多个次维表(常变更),因为维表一般有严格的时间要求与依赖任务,同时对与需要经常修改的任务做回跑有利,例如我们为声波用户设计了基础的dim_slive_user_base_d主维表和指标丰富的dim_slive_user_d次维表。
DWD一般是基于具体业务过程,构建最细粒度的明细层事实表,也可以将明细事实表的某些重要维度属性字段做退化设计,这里也可以添加一些常用统计口径的杂项维度。例如消费明细表中并不是每一笔消费都是计入KPI的,可以添加一些is_real_consume(是否实际消费)、is_consume_water(是否消费流水)、is_operation(是否运营操作),这样便于下游的统计。
DWS以分析的主题对象作为建模驱动,将相对应的事实进行聚合统计,形成一些轻度聚合、中度聚合或者重度聚合的宽表。
任务调度设置
任务流建设是对整个业务过程的横向分层,下表是声波业务的任务分层,也是契合于上述的数据分层。

优缺点:
优点:相对于单表单任务流来讲,任务流依赖配置简单,同时易读性高;对于有依赖的任务可一次性提交回跑任务;核心任务能够及时产出。
缺点:相对于单表单单任务流来讲,定位某表属于那个任务流相对较慢;某些核心任务报表产出相对延迟些。
注意:
当调度任务失败时,要在实例详情页面进行重跑;
一般依赖任务的开始调度时间要晚于被调度的任务;
ads层表从dim/dwd/dws层来调用,不要直接走ods层。
声波OLAP取数模型及流量自动化
3.1现有设计
快速便捷获取高质量数据是业务侧的希冀,同时为减少ad-hoc式的查询也是我们的希冀。因此构建声波olap模型,目标是帮助业务人员快速使用数据,获取结果并用于业务生产。
取数模型设计:
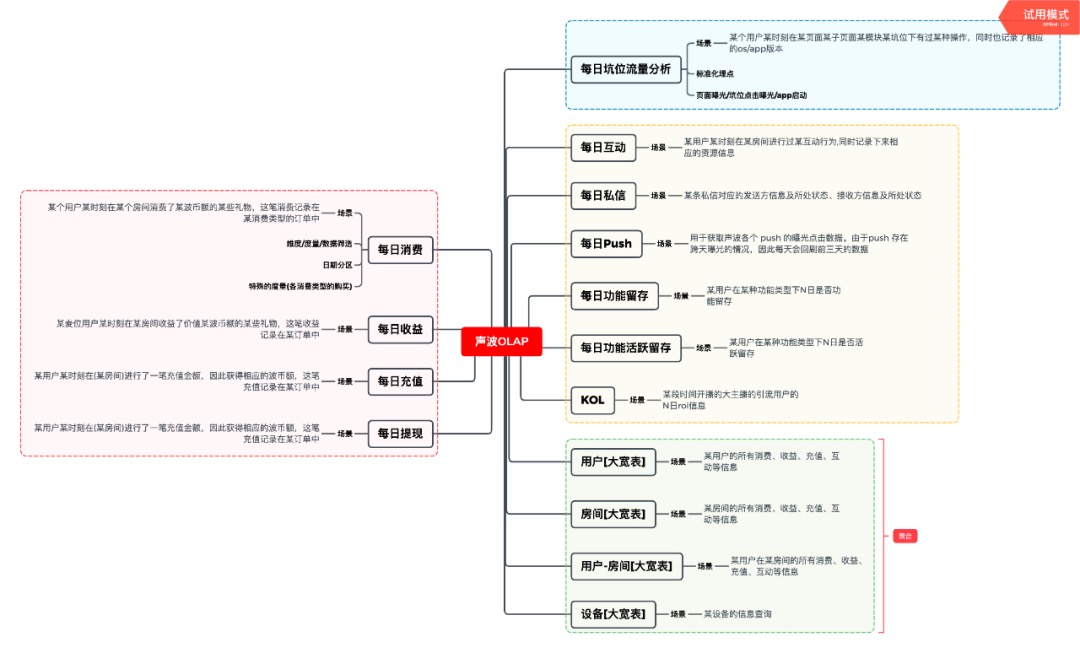
目前模型建设流程:
业务侧/已有报表中归纳常用指标
模型设计(常分析的业务过程(交易、互动)的明细、用户、房间、用户+房间的汇总表)
模型评审
配置模型(使用场景的说明、字段业务口径、技术口径、添加自定义维度、自定义度量)
测试使用
流量自动化的解决方案:
策划梳理坑位信息-〉与策划勾兑坑位信息-〉设计埋点scm信息-〉上传埋点到埋点平台-〉与开发勾兑埋点内容–〉下载最终版坑位信息制作坑位码表。
设计流量自动化的聚合表模型:uid+os+appver+mspm+source(+房间id+房间模版类型id)的粒度统计对应的(曝光、点击、进房)次数、人数和时长等信息。构建流量自动化模型,最终可由取数展示,该模型可以查看日常曝光点击的坑位PV、UV,同时可以查看核心(曝光-点击-进房)漏斗数据。
3.2思考
目前存在的难点,这些都是后期会优化的内容。
数据侧:a.模型设计(聚合、解耦) b.模型迭代回跑
平台侧:a.平台开发进度无法满足模型使用 b.问题响应速度依赖其他部门
业务侧:a.对数据的维度、度量、聚合、日期分区的理解困难 b.自主分析数据的习惯尚未建立



