一、yarn产生背景(yarn设计理念与基本架构)
学习了董西成的Hadoop技术内幕第二章总结回顾
由于MRv1在扩展性、可靠性、资源利用率和多框架等方面存在明显不足,Apache开始尝试对MapReduce进行升级改造,于是诞生了更加先进的下一代MapReduce计算框架MRv2。由于MRv2将资源管理模块构建成了一个独立的通用系统YARN,这直接使得MRv2的核心从计算框架MapReduce转移为资源管理系统YARN。
MRv1 的局限性
YARN是在MRv1基础上演化而来的,它客服了MRv1中的各种局限性。在正式介绍YARN之前,我们先要了解MRv1的一些局限性。
包括如下几个方面:
- 1、扩展性差。
- 2、可靠性查。
- 3、资源利用率低。
- 4、无法支持多种计算框架。
扩展性差
在MRv1中,JOBTracker同时兼备了 资源管理 和 作业控制 两个功能,这成为系统的一个最大瓶颈,严重制约了Hadoop集群的扩展性。
可靠性差
MRv1采用了master/slave结构,其中,master存在单点故障问题,一旦它出现故障将导致整个集群不可用。
资源利用率低
MRv1采用了基于槽位的资源分配模型,槽位是一种粗粒度的资源划分代为,通常一个任务不会用完槽位对应的资源,
且其他任务也无法使用这些空闲资源。
此外,Hadoop将槽位分为MapSlot和ReduceSlot两种,且不允许它们之间共享,常常会导致一种槽位资源紧张
而另外一种闲置(比如一个作业刚刚提交时,只会运行Map Task,此时Reduce Slot闲置)。
无法支持多种计算框架
MapReduce这种基于磁盘的离线计算框架已经不能满足应用要求,从而出现了一些新的计算框架,包括内存计算框架、
流式计算框架和迭代式计算框架等,而MRv1不能支持多种计算框架并存。
怎么办?
为了克服以上几个缺点,Apache开始尝试对Hadoop进行升级改造,进而诞生了更加先进的下一代
MapReduce计算框架MRv2。正是由于MRv2将资源管理功能抽象成了一个独立的通用系统YARN,直接导致
下一代MapReduce的核心从单一的计算框架MapReduce转移为通用的资源管理系统YARN。
轻量级弹性计算平台
考虑到资源利用率、运维成本、数据共享等因素,公司一般希望将所有这些框架都部署到一个公共的集群中,
让它们共享集群的资源,并对资源进行统一使用,
同时采用某种资源隔离方案(如轻量级cgroups)对各个任务进行隔离,这样便诞生了轻量级弹性计算平台,
如图所示。YARN便是弹性计算平台的典型代表。
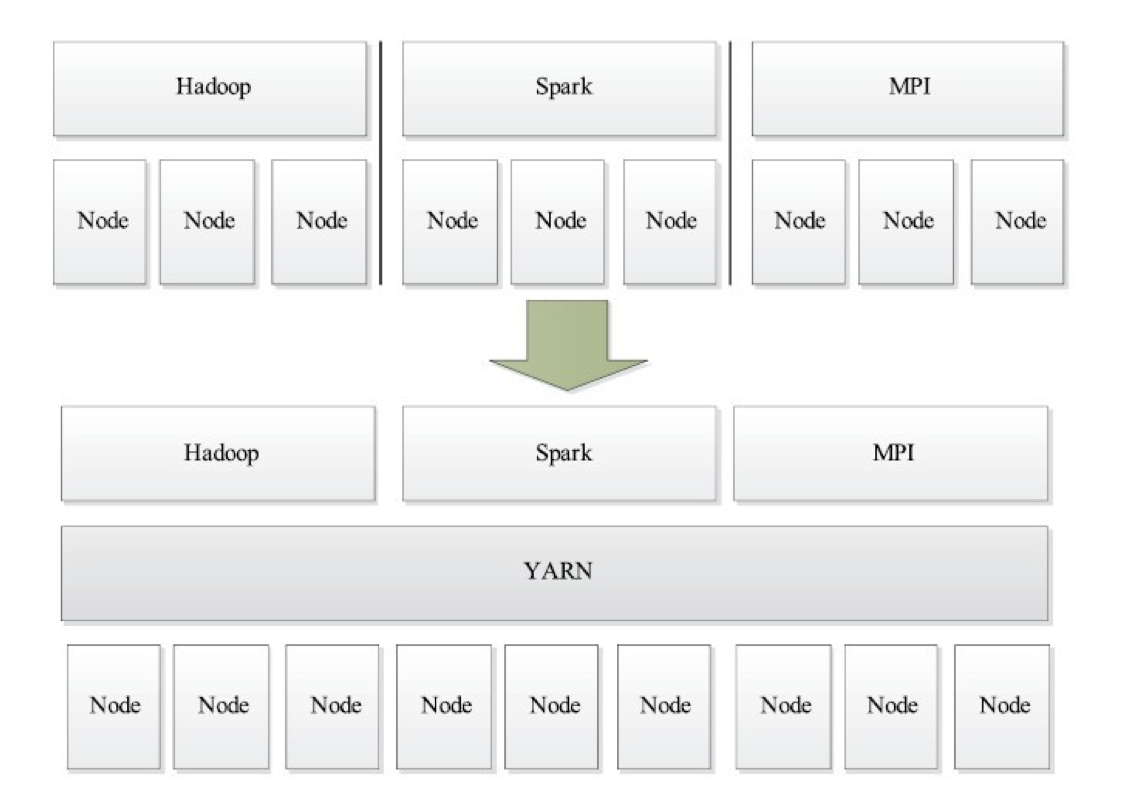
从上面可知,YARN实际上是一个弹性计算平台,它的目标已经不再局限于支持MapReduce一种计算框架,而是朝着多种框架进行统一管理的方向发展。
相比于”一种计算框架一个集群”的模式,共享集群的模式存在多种好处:
- 1、资源利用率高
- 2、运维成本低
- 3、数据共享
资源利用率高
共享集群模式则通过多种框架共享资源,使得集群中的资源得到更加充分的利用。
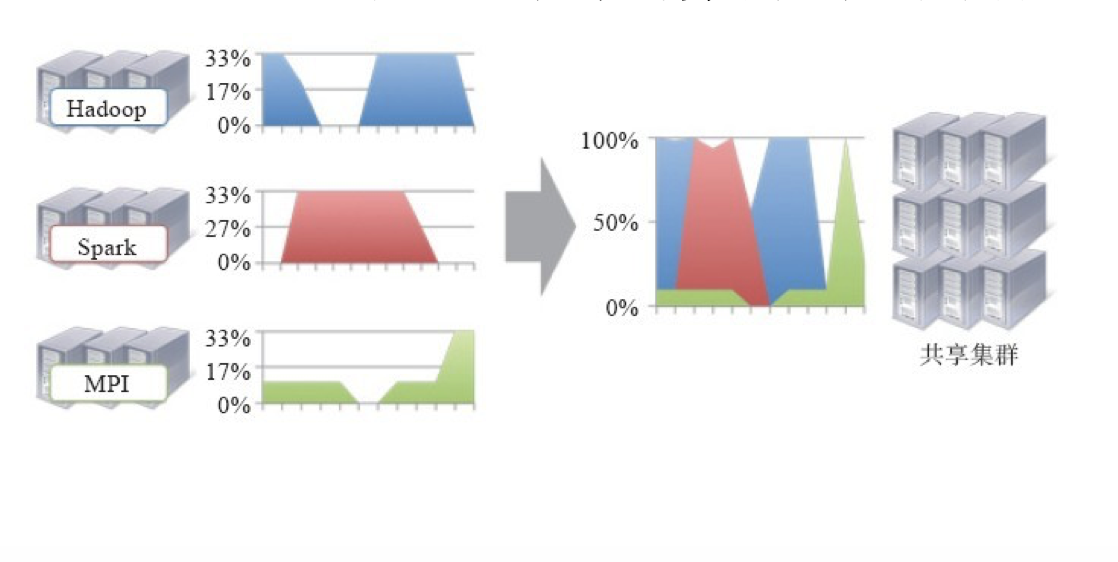
运维成框架本低
如果采用”一个框架一个集群”的模式,则可能需要多个管理员管理这些集群,进而增加运维成本,
而共享模式通常需要少数管理员即可完成多个框架的统一管理。
数据共享
随着数据量的暴增,跨集群间的数据移动不仅需花费更长的时间,且硬件成本也会大大增加,而共享集群模式
可让多种框架共享数据和硬件资源,将大大减小数据移动带来的成本。



