二、Hadoop基础知识(yarn设计理念与基本架构)
学习了董西成的Hadoop技术内幕第二章总结回顾
术语解释
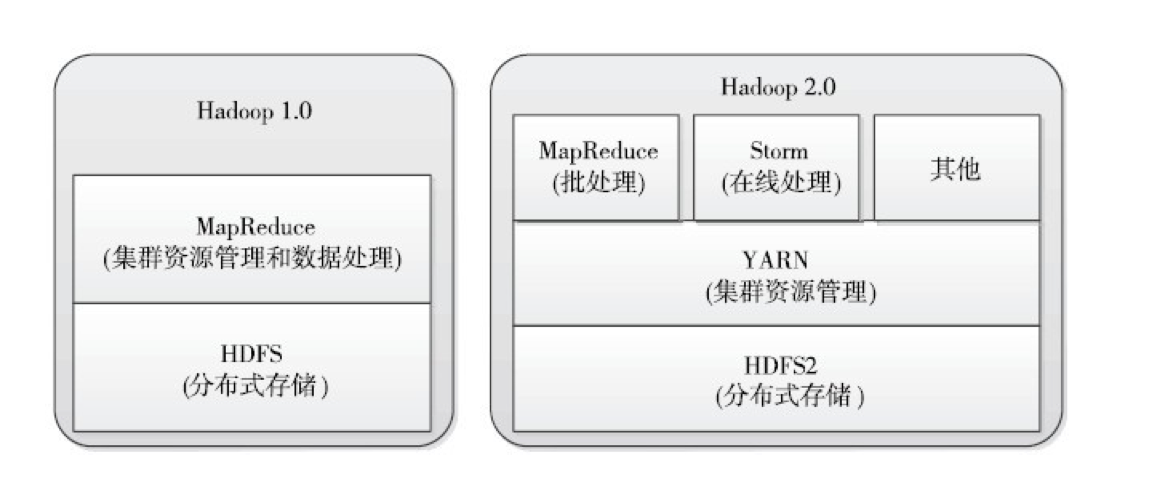
Hadoop 1.0
Hadoop 1.0 即第一代Hadoop,由分布式存储系统HDFS和分布式计算框架MapReduce组成,其中,
HDFS由一个NameNode和多个DataNode组成,MapReduce由一个JobTracker和多个TaskTracker组成。
Hadoop 2.0
Hadoop 2.0即第二代 Hadoop,为客服Hadoop 1.0中HDFS和MapReduce存在的各种问题而提出的。
针对Hadoop 1.0中的蛋NameNode制约HDFS的扩展性问题,提出了HDFS Federation,它让多个NameNode分管不同的目录
进而实现访问隔离和横向扩展,同时它彻底解决了NameNode单点故障问题;针对Hadoop 1.0中的
MapReduce在扩展性和多框架支持等方面的不足,它将JobTracker中的资源管理和作业控制
功能分开,分别由组件ResourceManager和ApplicationMaster实现,其中,ResourceManager
负责所有应用程序的资源分配,而ApplicationMaster仅负责管理一个应用程序,进而诞生了权限的通用资源管理框架 YARN。基于YARN,用户可以运行各种类型的应用程序(不再像1.0那样仅局限于MapReduce一类应用)。
MapReduce 1.0或MRv1
MapReduce 1.0计算框架主要由三部分组成,分别是编程模型、数据处理引擎和运行时环境。
编程模型
编程模型是将问题抽象成Map和Reduce两个阶段,其中Map阶段将输入数据解析成key/value,
迭代调用map()函数处理后,再以key/value的形式输出到本地目录,
而Reduce阶段则将key相同的value进行规约处理,并将最终结果写入hdfs上。
数据处理引擎
数据处理引擎由MapTask和ReduceTask组成,分别负责Map阶段逻辑和Reduce阶段逻辑的处理。
运行时环境
它的运行时环境由(一个)JobTracker和(若干个)TaskTracker两类服务组成,
其中,JobTracker负责资源管理和所有作业的控制,而TaskTracker负责接收来自
JobTracker的命令并执行它。
MRv2
MRv2具有与MRv1相同的编程模型和数据处理引擎,唯一不同的是运行时环境。
MRv2是在MRv1基础上经加工之后,运行于资源管理框架YARN之上的计算框架MapReduce。
它的运行时环境不再由JobTracker和TaskTracker等服务组成,
而是变为通用资源管理系统YARN和作业控制进程ApplicationMaster,其中,YARN负责资源管理和调度,
而ApplicationMaster仅负责一个作业的管理。
简而言之,MRv1仅是一个独立的离线计算框架,而MRv2则是运行于YARN之上的MapReduce。
YARN
YARN是Hadoop 2.0中的资源管理系统,它是一个通用的资源管理模块,可为各类应用程序进行资源管理和调度。
YARN不仅限于MapReduce一种框架使用,也可以提供其他框架使用。
由于YARN的通用性,下一代MapReduce的核心已经从简单的支持单一应用的计算框架MapReduce转移到通用的资源管理系统YARN。
HDFS Federation
Hadoop2.0中对HDFS进行了改进,使NameNode可以横向扩展成多个,
每个NameNode分管一部分目录,进而产生了HDFSFederation,该机制的引入不仅增强了HDFS的扩展性,也使HDFS具备了隔离性。
先介绍几个独立产生ApacheHadoop新版本的重大特性:
###1、Append
HDFSAppend主要完成追加文件内容的功能,也就是允许用户以Append方式修改HDFS上的文件。HDFS最初的一个设计目标是支持MapReduce编程模型,而该模型只需要写一次文件,之后仅进行读操作而不会对其修改,即”writeoncereadmany”,
这就不需要支持文件追加功能。但随着HDFS变得流行,一些具有写需求的应用想以HDFS作为存储系统,比如,有些应用程序需要往HDFS上某个文件中追加日志信息,HBase需使用HDFS具有Append功能以防止数据丢失等。
###2、HDFSRAID
HadoopRAID模块在HDFS之上构建了一个新的分布式文件系统DistributedRaidFileSystem(DRFS),该系统采用了ErasureCodes增强对数据的保护,有了这样的保护,可以采用更低的副本数来保持同样的可用性保障,进而为用户节省大量存储空间。
###3、Symlink
让HDFS支持符号链接。符号链接是一种特殊的文件,它以绝对或者相对路径的形式指向另外一个文件或者目录(目标文件),当程序向符号链接中写数据时,相当于直接向目标文件中写数据。
###4、Security
Hadoop的HDFS和MapReduce均缺乏相应的安全机制,比如在HDFS中,用户只要知道某个block的blockID,便可以绕过NameNode直接从DataNode上读取该block,用户可以向任意DataNode上写block;在MapReduce中,用户可以修改或者杀掉任意其他用户的作业等。为了增强Hadoop的安全机制,从2009年起,Apache专门抽出一个团队,从事为Hadoop增加基于Kerberos和DeletionToken的安全认证和授权机制的工作。
###5、MRv1
正如前面所述,第一代MapReduce计算框架由三部分组成:编程模型、数据处理引擎和运行时环境。其中,编程模型由新旧API两部分组成;数据处理引擎由MapTask和ReduceTask组成;运行时环境由JobTracker和TaskTracker两类服务组成。
###6、MRv2/YARN
MRv2是针对MRv1在扩展性和多框架支持等方面的不足而提出来的,它将MRv1中的JobTracker包含的资源管理和作业控制两部分功能拆分开来,分别将由不同的进程实现。考虑到资源管理模块可以共享给其他框架使用,MRv2将其做成了一个通用的YARN系统,YARN系统的引入使得计算框架进入了平台化时代。
###7、NameNodeFederation
针对Hadoop1.0中NameNode内存约束限制其扩展性问题提出的改进方案,它使NameNode可以横向扩展成多个,其中,每个NameNode分管一部分目录,这不仅使HDFS扩展性得到增强,也使HDFS具备了隔离性。
###8、NameNodeHA
HDFSNameNode存在NameNode内存约束限制扩展性和单点故障两个问题,其中,第一个问题通过NameNodeFederation方案解决,而第二个问题则通过NameNode热备方案(NameNodeHA)实现。



