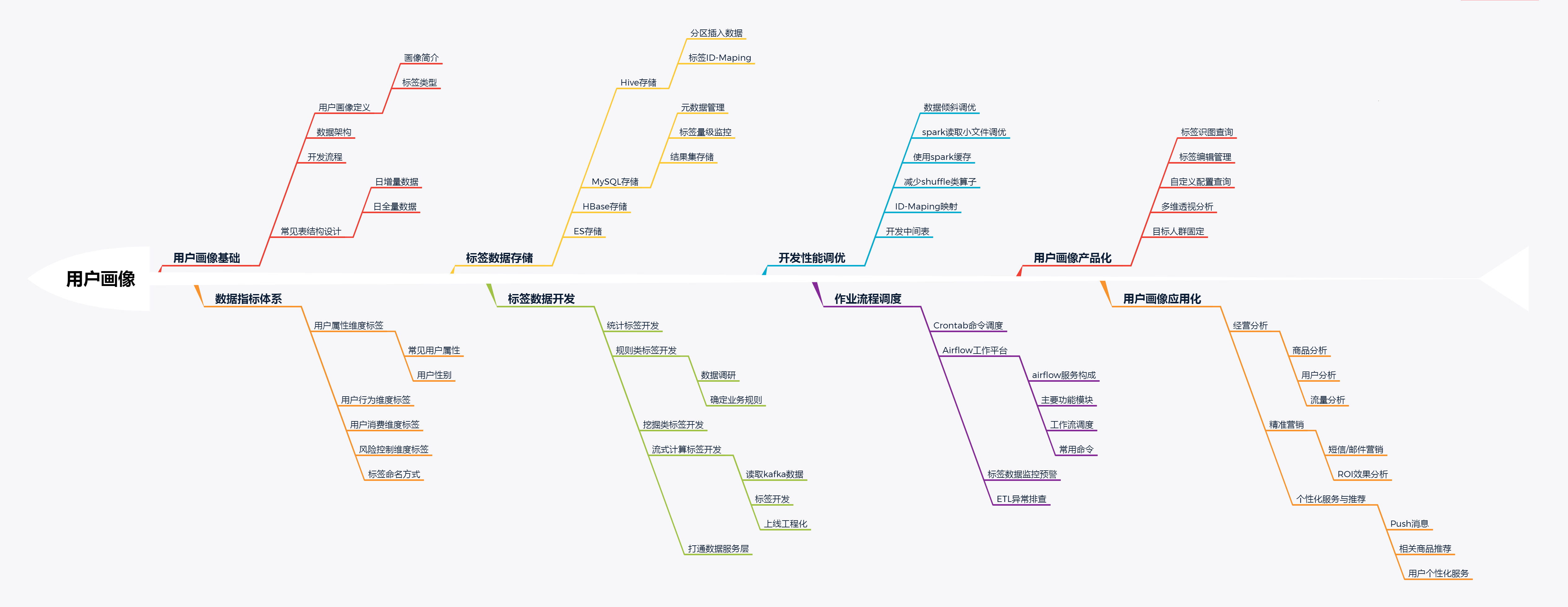
何为用户画像
用户画像,即用户信息标签化,户画像建模其实就是对用户“打标签”。通过收集与分析消费者社会属性、生活习惯、消费行为等主要信息的数据之后,完美地抽象出一个用户的商业全貌作是企业应用大数据技术的基本方式。
用户信息标签分类
按照标签的变化频率,可分为静态标签和动态标签。
静态标签:是指用户与生俱来的属性信息,或者是很少发生变化的信息,比如用户的姓名、性别、出生日期,又例如用户学历、职业等,虽然有可能发生变动,但这个变动频率是相对比较低或者很少发生变化的。
动态标签:是指非常经常发生变动的、非常不稳定的特征和行为,例如“一段时间内经常去的商场、购买的商品品类”这类的标签的变动可能是按天,甚至是按小时计算的。
按照标签的指代和评估指标的不同,可分为定性标签和定量标签。
定性标签:指不能直接量化而需通过其他途径实现量化的标签,其标签的值是用文字来描述的,例如“用户爱好的运动”为“跑步、游泳”,“用户的在职状态”为“未婚”等。定量标签指可以准确数量定义、精确衡量并能设定量化指标的标签,其标签的值是常用数值或数值范围来描述的。
定量标签:并不能直观的说明用户的某种特性,但是我们可以通过对大量用户的数值进行统计比较后,得到某些信息。例如“用户的年龄结构”为“20-25岁”、“单次购买平均金额”为“300元”,“购买的总金额”为“20万元”……,当我们获得以上信息是否就可以将该用户划分为高价值客户呢?
按照标签的来源渠道和生成方式不同,可以分为基础标签、业务标签、智能标签。
基础标签:主要是指对用户基础特征的描述,比如:姓名、性别、年龄、身高、体重等。
业务标签:是在基础标签之上依据相关业务的业务经验并结合统计方法生成的标签,比如:用户忠诚度、用户购买力等标签就是根据用户的登录次数、在线时间、单位时间活跃次数、购买次数、单次购买金额、总购买金额等指标计算出来的。业务标签可以将经营固化为知识,为更多的人使用。
智能标签:是利用人工智能技术基于机器学习算法,通过大量的数据计算而实现的自动化、推荐式的进行打标签,比如今日头条的推荐引擎就是通过智能标签体系给用户推送其感兴趣的内容的。
按照数据提取和处理的维度,可以将标签分为事实标签,模型标签,预测标签。
事实标签:既定事实,直接从原始数据中提取,描述用户的自然属性、产品属性、消费属性等,事实标签其本身不需要模型与算法,实现简单,但规模需要不断基于业务补充与丰富,比如:姓名、购买的产品品类、所在小区等。
模型标签:对用户属性及行为等属性的抽象和聚类,通过剖析用户的基础数据为用户贴上相应的总结概括性标签及指数,标签代表用户的兴趣、偏好、需求等,指数代表用户的兴趣程度、需求程度、购买概率等。
预测标签:参考已有事实数据,基于用户的属性、行为、位置和特征,通过机器学习、深度学习以及神经网络等算法进行用户行为预测,针对这些行为预测配合营销策略、规则进行打标签,实现营销适时、适机、适景推送给用户。例如试用了某产品A后预测可能还想买产品B并推送购买链接给该用户,买了狗粮就可能养宠物,了解了减肥产品可能就打算减肥等等
按照标签体系分级分层的方式,可以分为一级标签、二级标签、三级标签等。
每一个层级的标签相当于一个业务维度的切面。在标签应用中按照不同的业务场景进行标签组合,形成相应用户画像。
用户信息标签建模
用户画像模块
用户信息标签开发步骤
标签类型选择划分,细分级别和业务命名
这一步确定该使用何种维度去划分标签,是最关键的一步,需要结合实际业务去划分适合自己业务的维度,然后使用脑图的形式输出具体的划分级别和命名。命名最好是中英文对照关系,方便后期标签命名组合。数据采集
有了第一步的脑图,就需要寻找出各个实际业务类型下需要的数据。数据清洗
大家都知道大数据有一个特征Value(价值密度低),在标签体系的建设是在大数据环境下进行的,大数据的低价值密度性决定着在采集回来的数据中存在着大量的噪声数据、脏数据,比如:缺失值、重复、数值异常等。要实现精准的用户画像就需要对这些噪声数据、脏数据进行处理,这个过程我们叫做数据清洗。数据标准化
比如在这一步可能需要处理好枚举值到底用数字还是具体的中文释义,多账户问题,比如一个用户可能使用多个设备,拥有多个账号,则须把多个身份ID组合,建立统一的标准,形成完整标识实体的用户画像,这个场景被称为OneID体系——统一身份认证,即对于同一个人,使用不同设备或系统只有唯一身份。数据建模
数据建模就是根据用户行为,构建模型产出标签、权重。一个事件模型包括:时间、地点、人物三个要素。每一次用户行为本质上是一次随机事件,可以详细描述为:什么用户,在什么时间,什么地点,做了什么事。
用户动态建模公式:用户标识 +时间 + 行为类型 + 接触点(网址+内容),表示某用户在什么时间、地点、做了什么事,所以会打上某标签。用户标签的权重可能随时间的增加而衰减,因此定义时间为衰减因子r,行为类型,同时该标签对该用户的重要程度也决定了用户标签的权重,进一步转换为公式:
用户标签权重 = 行为类型权重 × 时间衰减 × 用户行为次数 × TF-IDF计算标签权重
- 行为类型权重:用户浏览、搜索、收藏、下单、购买等不同行为对用户而言有着不同的重要性(偏序关系),该权重值一般由运营人员或业务来决定;
- 时间衰减:用户某些行为受时间影响不断减弱,行为时间距现在越远,该行为对用户当前来说的意义越小,采用牛顿冷却定律;
- 行为次数:用户标签权重按天统计,用户某天与该标签产生的行为次数越多,该标签对用户的影响越大。
公式:t=初始温度×exp(-冷却系数×间隔的时间),实际应用中,初始温度为1就行,间隔的时间为今天与产生行为那天的天数,或者小时数都行,根据业务进行调整,冷却系数的业务来决定,或者通过数据分析而来。
TF-IDF计算标签权重:tf为某标签在该用户出现频率,idf为某标签在全部标签中的稀缺程度。
比如: 一个妹子的标签:王者荣耀0.4,电商0.1,看书0.2,就是行为权重,很明显这段时间喜欢玩王者荣耀
数据标签落库
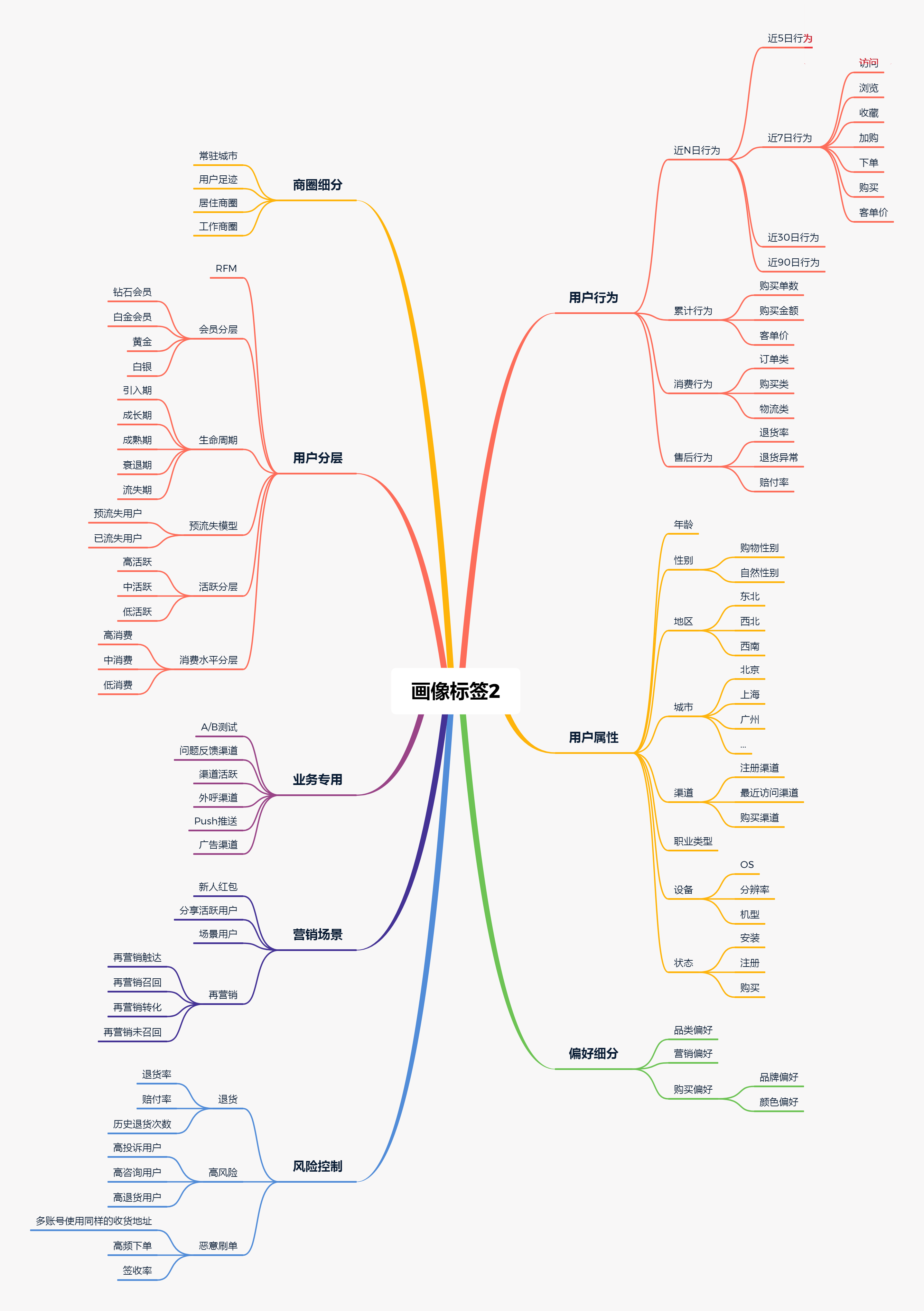
标签api产出,标签可视化用户画像应用
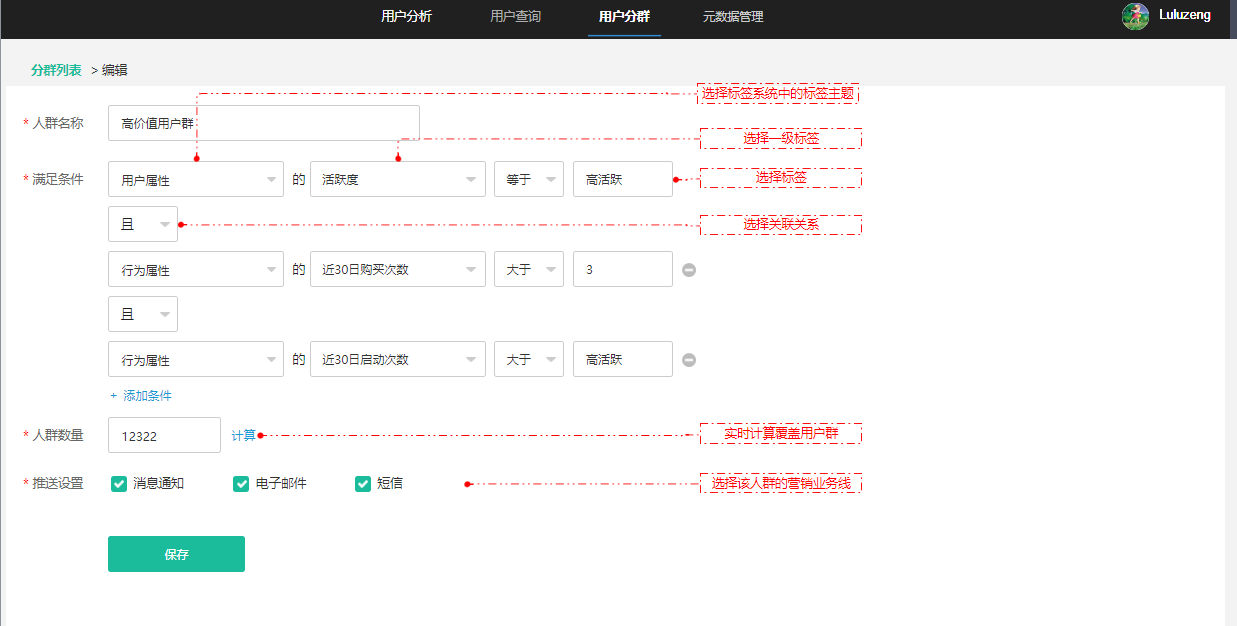
用户标签维度
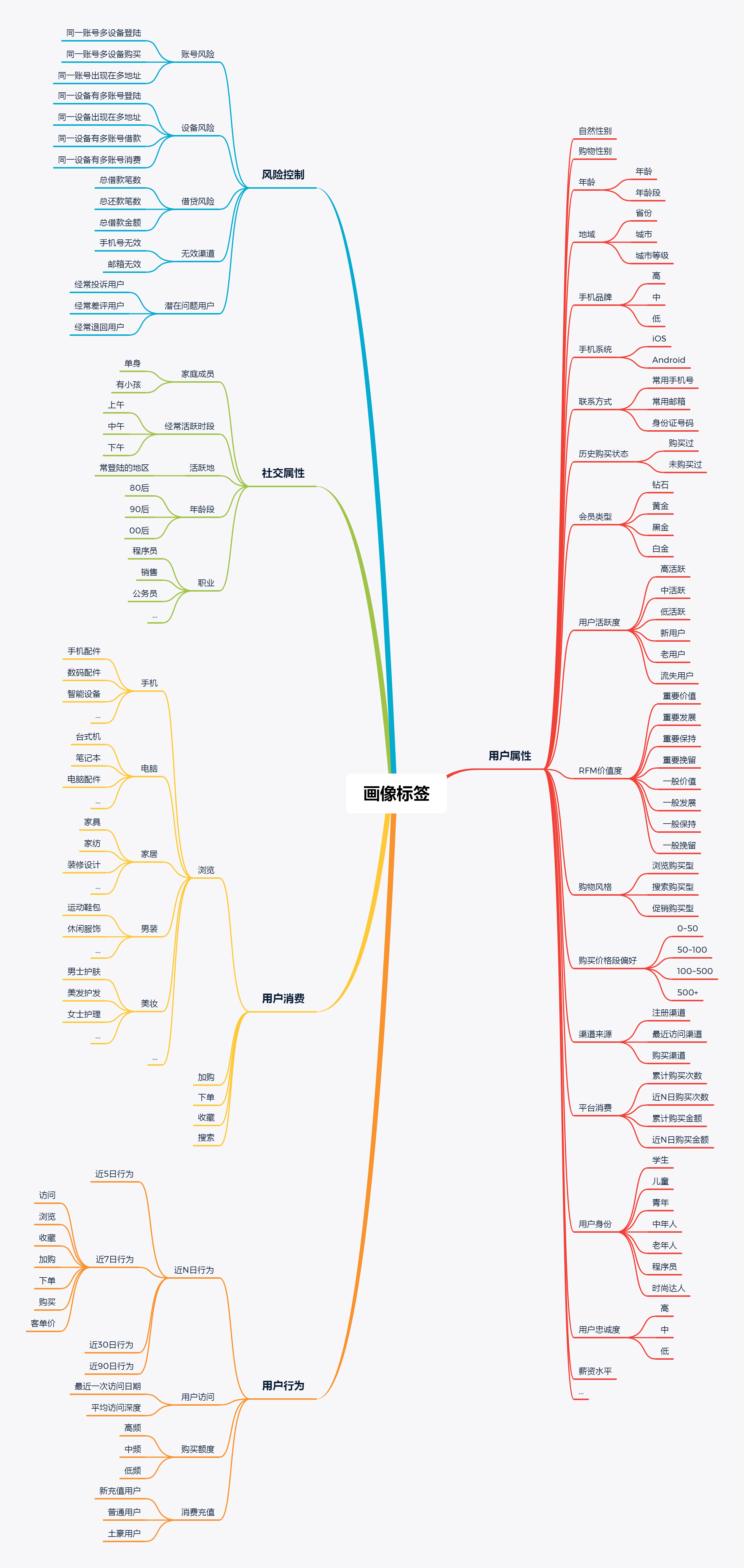
用户标签命名规范
标签主题
标明属于哪个类型的标签,如人口属性(ATTRITUBE),行为属性(ACTION),用户消费(CONSUME),风险控制(RISKMANAGE)等。用户维度
表明该标签来源,是用户唯一标识(userid),还是用户设备(cookie),一般用U和C区分。一般常用userid,因为用户设备这块不同操作系统对应的唯一标识可能会有区别,而且在关联用户的时候会比较麻烦。标签类型
标签分类,统计型(01)、规则型(02)、算法型(03)。一级归类
在每个标签大类下面,进一步细分的标签类型。
参照上面的命名方式,举例用户的性别标签:
命名规则:标签主题_用户维度_标签类型_一级归类
1 | 【男】:ATTRITUBE_U_01_001 |
以上只是理论,但是实际使用中需要内化灵活使用, 比如性别就只有一个标签就好,就标示男女。
表设计
1 | CREATE TABLE dw_userprofile_userlabel_all( |
引用
https://www.jianshu.com/u/9d13e03e7e9f
https://mp.weixin.qq.com/s?__biz=MzI5OTk5OTM2Mw==&mid=2247510010&idx=1&sn=f1724c4a11d91bdc4b3714e3c5ef1315&chksm=ec8cee16dbfb6700ff59486546223e9578ec1e86b71c9bab18e2a8ff1e981e65e9d5e846d88f&mpshare=1&scene=24&srcid=0724S96C17ezc5XWrUqqpxPv&sharer_sharetime=1595552946286&sharer_shareid=6cb50fbe34a273e0189ae28f7c2c9f49#rd



