Spark 倒排索引的实现
啥是倒排索引(也有叫反向索引)inverted index
倒排索引(inverted index)源于实际应用中需要根据属性的值来查找记录。在索引表中,每一项均包含一个属性值和一个具有该属性值的各记录的地址。由于记录的位置由属性值确定,而不是由记录确定,因而称为倒排索引。将带有倒排索引的文件称为倒排索引文件,简称倒排文件(inverted file)
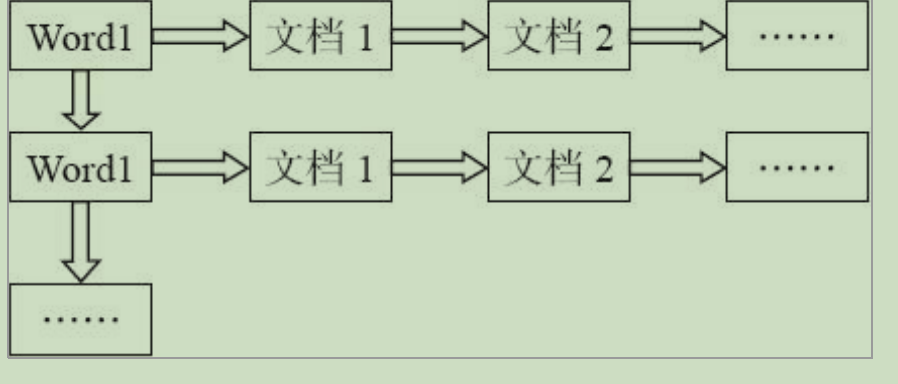
当我们搜索word1时就返回相应的地址,搜索引擎的基本工作原理就是这样。
spark 题目
输入
id1 Spark Hadoop Hive
id2 Spark Hive Sqoop
id3 Flink Hadoop Kafka
输出
Spark id1 id2
Hadoop id1 id3
Hive id1 id2
Flink id3
Sqoop id2
Kafka id3



