Spark SQL 运行流程简述(☆☆☆☆)
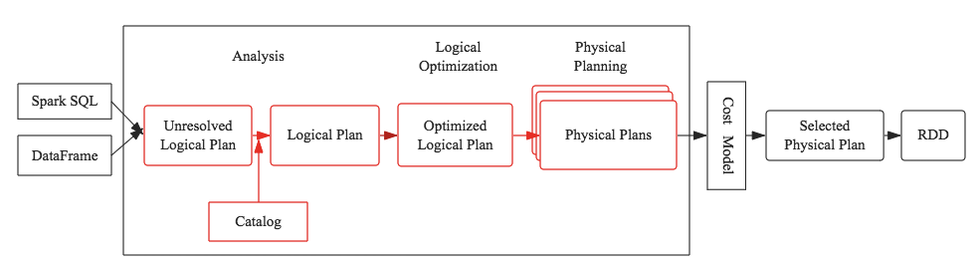
SparkSql整个解析成RDD的流程图,红色部分便是SparkSql优化器系统Catalyst,和大多数大数据SQL处理引擎设计基本相同(Impala、Presto、Hive(Calcite)等)
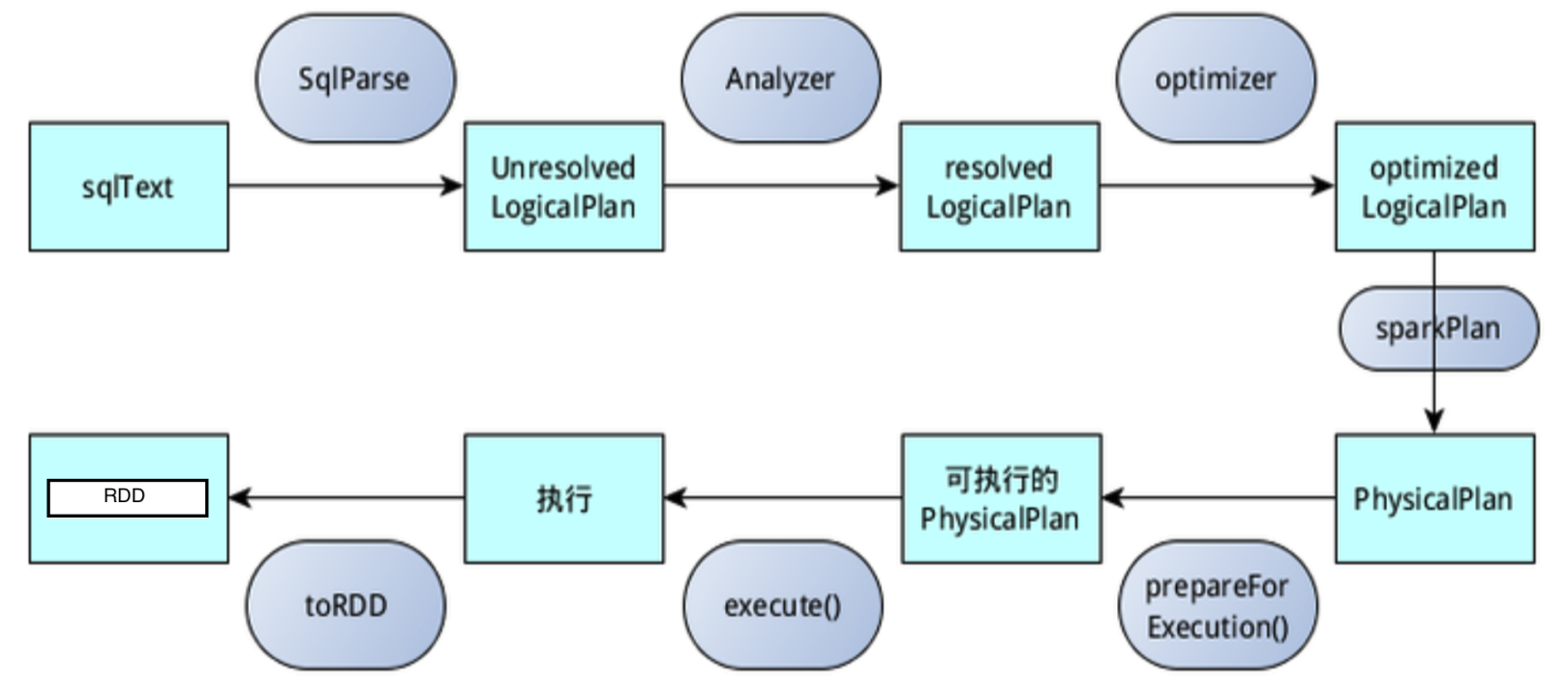
Parser
- sqlText先通过SparkSqlParser生成语法树。
- Spark1版本使用的是scala原生的parser语法解析器,从2.x后改用的是第三方语法解析工具ANTLR4,只需要定制好语法,可以通过插件自动生成对应的解析代码。
- 然后通过AstBuilder配合antlr的visitor模式自主控制遍历Tree,将antlr里面的节点都替换成catalyst(优化器系统)里面的类型,所有的类型都继承了TreeNode特质,TreeNode又有子节点children: Seq[BaseType],便有了树的结构。
- 此过程解析完后形成的AST(抽象语法树)为 unresolved LogicalPlan。
Analyzer
- 上个步骤还只是把sql字符串通过antlr4拆分并由SparkSqlParser解析成各种LogicalPlan(TreeNode的子类),每个LogicalPlan究竟是什么意思还不知道。
- 接下来就需要通过Analyzer去把不确定的属性和关系,通过catalog和一些适配器方法确定下来,比如要从Catalog中解析出表名user,是临时表、临时view,hive table还是hive view,schema又是怎么样的等都需要确定下来。
- 将各种Rule应用到Tree之上的真正执行者都是RuleExecutor,包括后面的Optimizer 也继承了RuleExecutor, 解析的套路是递归的遍历,将新解析出来的LogicalPlan来替换原来的LogicalPlan。
- 此过程解析完后形成的AST为 resolved LogicalPlan。若没有action操作,后续的优化,物理计划等都不会执行。
Optimizer
- 这个步骤就是根据大佬们多年的SQL优化经验来对SQL进行优化,比如谓词下推、列值裁剪、常量累加等。
- Optimizer 也继承了RuleExecutor,并定义了一批规则,和Analyzer 一样对输入的plan进行递归处理,此过程解析完后形成的AST为 optimized LogicalPlan。
SparkPlanner
通过优化后的LogicalPlan还只是逻辑上的,接下来需要通过SparkPlanner 将optimized LogicalPlan应用到一系列特定的Strategies上,即转化为可以直接操作真实数据的操作及数据和RDD的绑定等,此过程解析完后形成的AST为 PhysicalPlan。
prepareForExecution
此模块将 physical plan 转化为 executable physical plan,主要是插入 shuffle 操作和 internal row 的格式转换。
execute
最后调用SparkPlan的execute()执行计算。每个SparkPlan里面都有execute的实现,一般都会递归调用children的execute()方法,最后便会触发整个Tree的计算。