聊一聊MapReduce的Shuffle过程吧(☆☆☆)
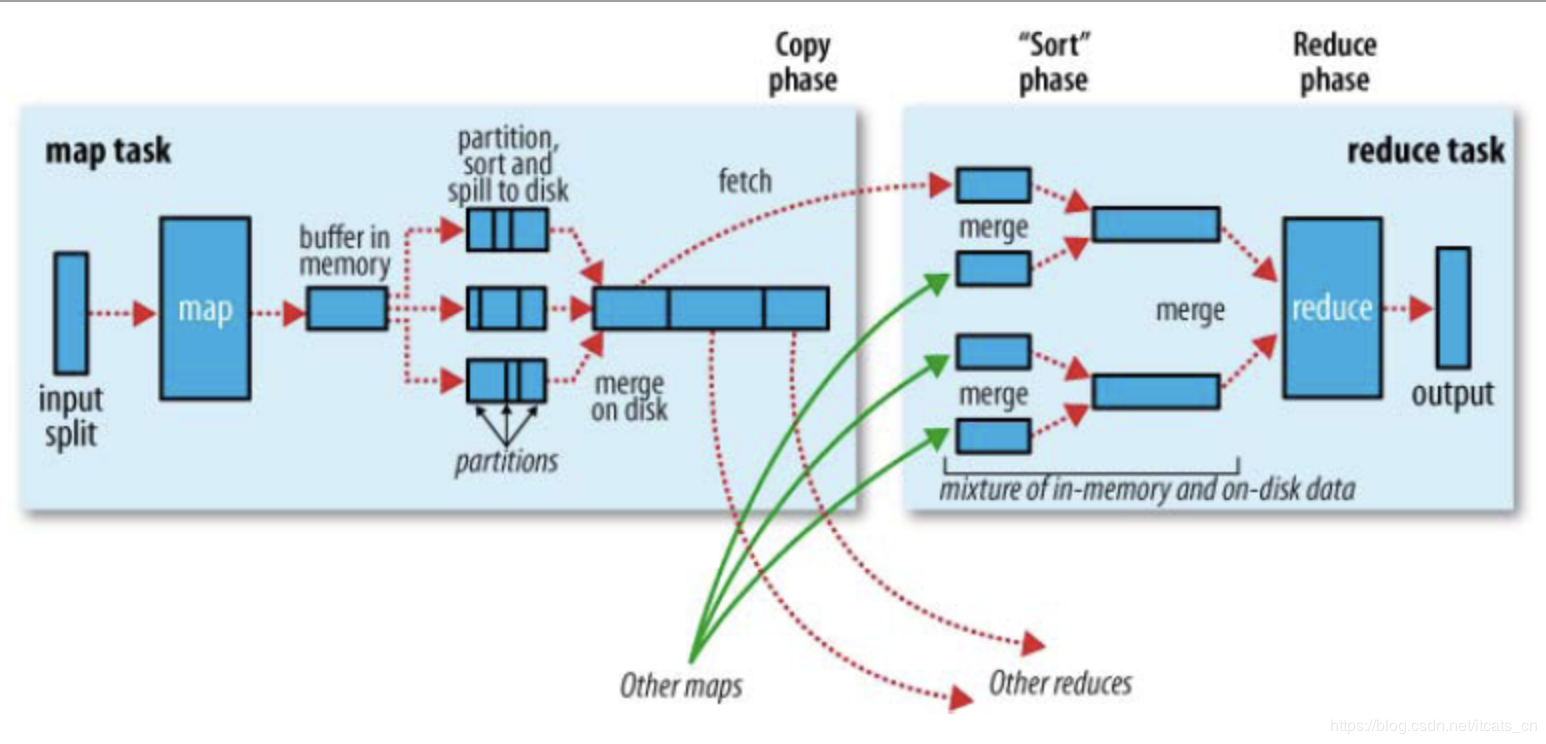
- Map 方法之后 Reduce 方法之前这段处理过程叫 Shuffle
- Map 方法之后,数据首先进入到分区方法,把数据标记好分区,然后把数据发送到
环形缓冲区;环形缓冲区默认大小 100m,环形缓冲区达到 80%时,进行溢写;溢写前对数
据进行排序,排序按照对 key 的索引进行字典顺序排序,排序的手段快排;溢写产生大量溢
写文件,需要对溢写文件进行归并排序;对溢写的文件也可以进行 Combiner 操作,前提是
汇总操作,求平均值不行。最后将文件按照分区存储到磁盘,等待 Reduce 端拉取。 - 每个 Reduce 拉取 Map 端对应分区的数据。拉取数据后先存储到内存中,内存不够
了,再存储到磁盘。拉取完所有数据后,采用归并排序将内存和磁盘中的数据都进行排序。
在进入 Reduce 方法前,可以对数据进行分组操作。



